
2023/08
JOEL SPOLSKY
有没有想过那个神秘的Content-Type标签?你知道应该把它放在HTML中,但你永远不知道它应该是什么?
你有没有收到过保加利亚朋友发来的电子邮件,主题是“???? ?????? ??? ????”?
我沮丧地发现,在字符集(character set)、编码(encoding)、Unicode等神秘的世界里,有多少软件开发人员并没有真正跟上进度。几年前,一位FogBUGZ的测试人员想知道它是否能处理日语的电子邮件。日语?他们有日语的电子邮件?我不知道。当我仔细观察我们用来解析MIME电子邮件的商业的ActiveX控件时,我们发现它在字符集上的做法是完全错误的,所以我们实际上不得不编写很难的代码来撤销它所做的错误转换,并重做正确的做法。当我查看另一个商业库时,它也有一个完全错误的字符相关的代码实现。我和那个软件包的开发人员通信,他认为他们“对此无能为力”。和许多程序员一样,他只是希望一切都能以某种方式结束。
然而并不会。当我发现流行的web开发编程语言PHP几乎完全不知道字符编码问题,愉快地使用8位字符,几乎不可能开发出良好的国际化web应用程序时,我想,适可而止吧。
因此,我要宣布:如果你是一名在2003年工作的程序员,你不知道字符、字符集、编码和Unicode的基本知识,而我抓住了你,我会惩罚你,让你在潜艇里剥6个月的洋葱。我发誓我会的。
其实也没有那么难。
在这篇文章中,我将向你详细介绍每个在职程序员应该知道的内容。所有关于“纯文本=ascii=字符为8位(bit)”的东西不仅是错误的,而且是无可救药的错误,如果你仍然以这种方式编程,你不会比一个不相信细菌的医生好多少。在读完这篇文章之前,请不要再写一行代码。
在我开始之前,我应该警告你,如果你是少数了解国际化的人之一,你会发现我的整个讨论有点过于简单化。我真的只是想在这里设置一个最低标准,这样每个人都能理解正在发生的事情,并编写代码,能处理除英语子集(其中不包括带口音的单词)之外的任何语言的文本。我应该警告你,字符处理只是创建国际通用软件所需的一小部分,但我一次只能写一件事,所以今天只写字符集相关的部分。
历史的视角
理解这些东西最简单的方法是按时间顺序排列。
你可能认为我会在这里谈论非常古老的字符集,比如EBCDIC。我不会的。EBCDIC与你的生活无关。我们不必回到那么远的过去。
回到中古时代,当Unix被发明,K&R正在编写C编程语言时,一切都很简单。EBCDIC正在退出。唯一重要的字符是老式无重音的英文字母,我们有一个名为ASCII的代码,它可以用32到127之间的数字表示每个字符。空格是32,字母“A”是65,等等。这可以方便地存储在7位二进制数中。当时的大多数计算机都使用8位的字节(译者注:1字节(Byte)由8位(bit)组成),所以你不仅可以存储每一个可能的ASCII字符,而且你还有一个多余的位(bit)可供使用,如果你很邪恶,你可以将其用于自己的邪恶目的。低于32的代码被用于编码不可打印的字符,并被用来咒骂。开个玩笑。它们被用于“控制字符”,比如7会让你的电脑发出嘟嘟声,12会让当前的一页纸飞出打印机,并输入新的一页。

假设你是一个英语世界的人,那么一切都很好。
因为1个字节最多可以容纳8位,所以很多人开始想,“天哪,我们可以把128到255这些代码用于自己的目的。”问题是,很多人同时也有这个想法,他们对128到255之间的空间也有自己的想法。IBM-PC有一种后来被称为OEM字符集的东西,它为欧洲语言提供了一些重音字符和一堆白描字符(line drawing characters)……水平条、垂直条、右侧悬挂着小叮当的水平条等等,你可以用这些白描字符在屏幕上制作漂亮的框和线,你仍然可以在干洗店的8088电脑上看到运行着它的程序。
{kind=link}

事实上,当人们开始在美国以外的地方购买电脑时,人们就想出了各种不同的OEM字符集,它们都将前128个字符用于自己的目的。例如,在一些电脑上,字符代码130会显示为é,但在以色列销售的电脑上,它是希伯来语字母Gimel(),所以当美国人将他们的简历résumés发送到以色列时,他们会以r
sum
s的形式到达。在许多情况下,比如俄罗斯人,对于如何处理128个以上的字符有很多不同的想法,所以你甚至无法可靠地与他们交换俄语文档。
最终,这个免费的OEM被编入了ANSI标准。在ANSI标准中,每个人都同意在128以下字符是什么,这与ASCII几乎相同,但根据你居住的地方,有很多不同的方法来处理128及以上的字符。这些不同的系统被称为代码页(code page)。例如,在以色列,DOS使用了一个名为862的代码页,而希腊用户使用的是737。128以下的字母相同,但128以上的字母不同,所有有趣的字母都在128以上。国际版本的MS-DOS操作系统有几十个这样的代码页,处理从英语到冰岛语的所有内容,他们甚至有几个“多语言”代码页,可以在同一台计算机上处理世界语和加利西亚语!哇!但是,除非你自己编写自定义程序,使用位图图形显示所有内容,否则在同一台计算机上获得希伯来语和希腊语是完全不可能的,因为希伯来语和希腊文需要不同的代码页,有不同的解释。
与此同时,在亚洲,更疯狂的事情正在发生,因为亚洲字母表有数千个字母,而这些字母用8位无法全部表示。这通常可以通过称为DBCS的混乱系统来解决,DBCS是一种“双字节字符集”,其中一些字母存储在一个字节中,另一些则存储在两个字节中。向前遍历一个字符串很容易,但向后遍历几乎是不可能的。鼓励程序员不要使用s++和s–来前后移动,而是调用Windows的AnsiNext和AnsiRev等知道如何处理整个混乱的函数。
但是,大多数人只是假装一个字节是一个字符,一个字符是8位,只要你从不把字符串从一台计算机移动到另一台计算机,或者你只说一种语言,这一假设就会一直起作用。但互联网一出现,把字符串从一台电脑转移到另一台电脑就变得很常见了,整个混乱局面随之而来。幸运的是,Unicode被发明了。
Unicode
Unicode是一项勇敢的努力,创建了一个包含地球上所有书写系统里合理的单个字符集,还包括一些像克林贡语这样的虚构的书写系统。有些人误解Unicode只是一个16位的字符集,每个字符占用16位,因此可能有65536个字符。事实上,这是不对的。这是关于Unicode的一个最常见的误解,所以如果你这么想的话,不要感到难过。
事实上,Unicode对字符有不同的思考方式,你必须理解Unicode对事物的思维方式,否则什么都没有意义。
到目前为止,我们一直假设一个字母映射到一些可以存储在磁盘或内存中的位:
A -> 0100 0001
在Unicode中,字母映射到一个称为代码点(code point,简称“码点”)的东西,这仍然只是一个理论上的概念。码点是如何在内存或磁盘中表示的,这是一个非常疯狂的故事。
在Unicode中,字母A是柏拉图式的理想化的东西。它只是漂浮在天堂:
A
这个柏拉图式的A不同于B,也不同于a,但与A、A(斜体)和A(粗体)相同。Times New Roman字体中的A与Helvetica字体中的A是相同的字符,但与小写的“a”不同,这一观点似乎没有太大争议,但在某些语言中,仅仅弄清楚字母是什么可能会引起争议。德语字母ß是一个真正的字母还是一种奇特的ss的书写方式?如果一个字母的形状在单词末尾发生变化,那是另一个字母吗?希伯来语(Hebrew)说是,阿拉伯语(Arabic)说不是。总之,Unicode委员会的聪明人在过去十年左右的时间里一直在想这个问题,伴随着大量高度政治化的辩论,你不必担心。他们已经想清楚了。
每个字母表中的每个柏拉图式的字母都被Unicode委员会分配了一个神奇的数字,例如:U+0639。这个神奇的数字被称为码点(code point)。U+的意思是“Unicode”,数字是十六进制的。U+0639是阿拉伯字母Ain的码点。英文字母A的码点是U+0041。你可以使用Windows 2000/XP上的charmap实用程序或访问Unicode网站来查找各种字母的码点或者通过码点来查找对应的字母。
Unicode可以定义的字母数量没有真正的限制,事实上,它们已经超过了65536个了,所以并不是每个Unicode字母都可以被压缩成两个字节,但无论如何,这都是一个神话。
好吧,假设我们有一个字符串:
Hello
在Unicode中对应以下5个码点:
U+0048 U+0065 U+006C U+006C U+006F
只是一堆码点。包括数字。我们还没有谈到如何将其存储在内存中或在电子邮件中如何表示。
编码(Encoding)
那就到了编码(encoding)出场的时候了。
Unicode编码最早的想法是,让我们把这些码点数字分别存储在两个字节中,这导致了关于两个字节的神话。所以Hello被存储为:
00 48 00 65 00 6C 00 6C 00 6F
对吗?不要那么快下结论!难道它也不能是:
48 00 65 00 6C 00 6C 00 6F 00
吗?好吧,从技术上讲,是的,我确实相信它可以,事实上,早期的实现者希望能够以大端(high-endian)或小端(low-endian)模式存储他们的Unicode码点,无论他们的CPU是快还是慢,瞧,现在已经有两种存储Unicode的方法了。因此,人们不得不想出一个奇怪的约定,在每个Unicode字符串的开头存储一个FE FF;这被称为Unicode字节顺序标记(Unicode Byte Order Mark),如果你交换高字节和低字节,它看起来就像一个FF FE,阅读你的字符串的人会知道他们必须每隔一个字节交换一次。唉,但是并非每一个Unicode字符串的开头都有一个字节顺序标记(译者注:有些程序员可能不知道或者不遵守“Unicode字节顺序标记”约定)。
有一段时间,这似乎已经足够好了,但程序员们一直在抱怨。“看看那些零!”他们说,因为他们是美国人,他们看的是英语文本,很少使用U+00FF以上的码点。此外,他们是加利福尼亚州的自由派嬉皮士,他们喜欢节约。如果他们是得克萨斯人,他们不会介意消耗两倍的字节数。但是,那些加州的懦夫无法忍受将字符串的存储量增加一倍的想法,而且无论如何,已经存在很多使用各种ANSI和DBCS字符集的该死的文档了,谁来转换它们呢?仅仅因为这个原因,大多数人就忽略Unicode很多年,与此同时,情况变得更糟了。
因此UTF-8这一绝妙的概念诞生了。UTF-8是另一种使用8位字节在内存中存储Unicode码点字符串(即神奇的U+数字)的系统。在UTF-8中,0到127的每个码点都存储在一个字节中。只有128及以上的码点使用2个字节,3个字节,实际上,最多使用6个字节来存储。
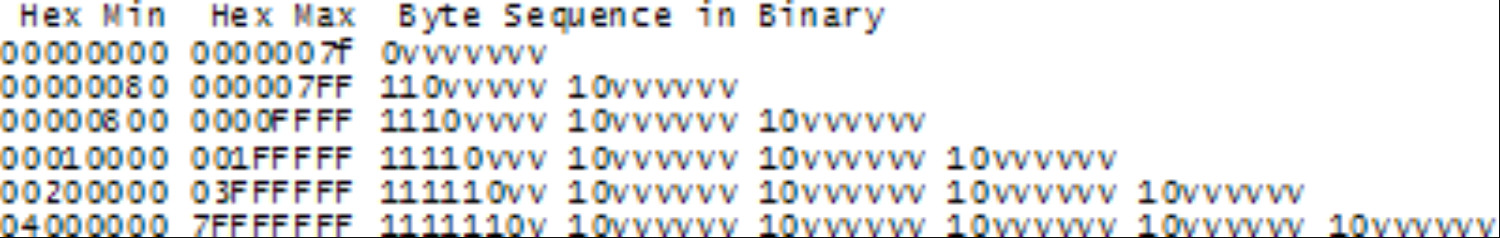
这有一个巧然,即英语文本在UTF-8中和在ASCII中看起来完全一样,所以美国人甚至不会注意到任何错误。只有世界上的其他地方才需要跳过重重关卡。具体来说,Hello字符串的Unicode码点是U+0048U+0065U+006CU+0006CU+006F,将被存储为UTF-8编码48656C6C6F,瞧!与存储在ASCII、ANSI和OEM字符集中的相同。现在,如果你大胆地使用重音字母、希腊字母或克林贡语(Klingon)字母,你将不得不使用几个字节来存储一个Unicode码点,但美国人永远不会注意到这些。(UTF-8还有一个很好的特性,即想要使用单个字节0作为null终止符的处理字符串的旧代码,任可正确运行)。
到目前为止,我已经告诉你编码Unicode码点的三种方法。传统的双字节存储方法被称为UCS-2(因为它使用两个字节)或UTF-16(因为使用16个bit),但你仍然需要弄清楚它是大端UCS-2还是小端UCS-2。还有一种流行的UTF-8标准,它有一个很好的特性,即英语文本和完全不知道除了ASCII字符之外还有其他东西的老程序,无需改动就可以正常工作。
实际上还有很多其他编码Unicode的方法。有一种叫做UTF-7编码的东西,它很像UTF-8,但保证高位总是零,所以如果你必须通过某种认为7位就足够了的严厉的警察国家的电子邮件系统来传递Unicode,谢谢你,它确实可以毫发无损地传递。还有有UCS-4编码,它将每个码点存储在4个字节中,它有一个很好的特性,即每个Unicode码点都可以存储在相同数量的字节中,但天哪,即使是德克萨斯人也不会这样大胆地浪费那么多内存。
现在你正在考虑的是可以用Unicode码点表示的柏拉图式的理想的字母,事实上,这些Unicode码点也可以用任何老式的编码方案编码!例如,你可以用ASCII编码Unicode字符串Hello(U+0048 U+0065 U+006C U+0006C U+006F),或者旧的OEM希腊编码,或者希伯来语ANSI编码,或者迄今为止发明的数百种编码中的任何一种,但有一个问题:有些字母可能无法显示出来!如果你试图在编码中表示的Unicode码点没有对应的可显示的字符,你通常会得到一个小问号:?,或者得到一个装在盒子里的小问号:�。
有数百种传统编码只能正确存储某些码点,并将所有其他码点显示为问号。一些流行的英语文本编码是Windows-1252(西欧语言的Windows 9x标准)和ISO-8859-1,也就是Latin-1(也适用于任何西欧语言)。但试着把俄语或希伯来语字母存储在这些编码中,你会得到一堆问号。UTF 7、8、16和32都具有能够正确存储任何码点的良好特性。
关于编码的一个最重要的事实
如果你完全忘记了我刚才解释的一切,请记住一个极其重要的事实——在不知道使用什么编码的情况下使用字符串是没有意义的。你不能再把头埋在沙子里,假装“纯”文本都使用ASCII编码。
没有“纯”文本这样的东西!
如果你在内存、文件或电子邮件中有一个字符串,你必须知道它的编码,否则你无法正确解析或向用户显示它。
几乎每一个愚蠢的“我的网站看起来像胡言乱语”或“当我使用重音符号时,她看不懂我的电子邮件”的问题都源于一个天真的程序员,他不明白一个简单的事实,即如果你不告诉我一个特定的字符串是使用UTF-8还是ASCII、ISO 8859-1(Latin 1)还是Windows 1252(西欧)编码的,你根本无法正确显示它,甚至无法弄清楚它的结束位置。码点127以上有一百多种编码,所有的赌注都是徒劳的。
我们如何保存关于使用的字符串编码的信息?好吧,有标准的方法可以做到这一点。对于电子邮件,你应该在表单的标头中有一个字符串:
Content-Type: text/plain; charset="UTF-8"对于网页,最初的想法是web服务器将返回一个包含类似于Content-Type字段的HTTP标头以及网页本身——Content-Type字段不是放在HTML内容本身中,而是在HTML页面之前发送的响应头里的字段之一。
这会导致一些问题。假设你有一个大型的网络服务器,里面有很多网站和数百个页面,这些网站和页面由很多人以各种不同的语言提供,并且都使用他们认为适合生成的Microsoft FrontPage副本的任何编码。web服务器本身并不真正知道每个文件是用什么编码编写的,因此无法发送Content-Type标头。
如果你可以使用某种特殊的标记将HTML文件的Content-Type直接放在HTML文件本身中,那将是非常方便的。当然,这会让纯粹主义者疯狂……你怎么能在知道HTML文件的编码之前阅读它呢?!幸运的是,几乎所有常用的编码都对32到127之间的字符做同样的事情,所以你总是可以在HTML页面里做到这一点:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">但这个元标记确实必须是<head>节的第一个标记,因为一旦web浏览器看到这个标记,它就会停止解析页面,并使用你指定的编码重新开始解释整个页面。
如果web浏览器在http响应头或元标记中找不到任何Content-Type,该怎么办?Internet Explorer实际上做了一件很有趣的事情:它试图根据各种语言的典型编码中各种字节在典型文本中出现的频率来猜测使用了什么语言和编码。因为各种旧的8位代码页倾向于将其国家字母放在128到255之间的不同范围内,而且因为每种人类语言在字母使用上都有不同的特征直方图,所以这种方法实际上是可行的。这真的很奇怪,但它似乎经常起作用,初级的网页作者从不知道自己需要一个“Content-Type”字段,他们在网络浏览器中查看自己的页面,看起来还可以,直到有一天,他们写的东西与他们母语的字母频率分布不完全一致,而Internet Explorer认为它是韩语并如此显示,我认为,坦率地说,波斯特尔定律(Postel’s Law)关于“保守输出,自由输入”的观点并不是一个好的工程原则。无论如何,这个网站是用保加利亚语写的,但似乎是韩语(甚至不一定是韩语),可怜的读者会怎么做?他使用“视图|编码”菜单,尝试一系列不同的编码(东欧语言至少有十几种),直到画面变得更清晰。但是大多数网站开发者都不会这么做。
对于我公司发布的网站管理软件CityDesk的最新版本,我们决定在内部使用UCS-2(两字节)Unicode,这是Visual Basic、COM和Windows NT/2000/XP使用的本地字符串类型。在C++代码中,我们只是将字符串声明为wchar_t(“wide char”)而不是char,并使用wcs系列函数而不是str系列函数(例如wcscat和wcslen而不是strcat和strlen)。要在C代码中创建一个文本UCS-2字符串,只需在其前面放一个L,例如L”Hello”。
当CityDesk发布网页时,它会将其转换为UTF-8编码,浏览器多年来一直很支持UTF-8编码。这就是Joel on Software所有29种语言版本的编码方式,我还没有听说有人在查看它们时遇到任何问题。
这篇文章越来越长了,我不可能涵盖关于字符编码和Unicode的所有知识,但我希望如果你读过这篇文章,你就知道了足够的知识,可以回到编程上来,使用抗生素而不是水蛭和咒语来治病,这是我现在留给你的任务。