
应该做完一个小的逻辑步骤(例如写完了一个或几个函数实现了一个小功能)就提交一次,完成一个模块就提交一次,这样方便代码回溯,也方便代码合并。不要写了大量代码后再提交一次,万一其中的一个小逻辑步骤的代码写错了,代码回滚后,大量其他正确的代码都白写了。
修改了之前的代码或注释,例如修复一个bug,也应该及时提交一次,而不是继续写完当前小功能的代码之后一起提交。
应该做完一个小的逻辑步骤(例如写完了一个或几个函数实现了一个小功能)就提交一次,完成一个模块就提交一次,这样方便代码回溯,也方便代码合并。不要写了大量代码后再提交一次,万一其中的一个小逻辑步骤的代码写错了,代码回滚后,大量其他正确的代码都白写了。
修改了之前的代码或注释,例如修复一个bug,也应该及时提交一次,而不是继续写完当前小功能的代码之后一起提交。
“家族传承吾辈责”是可以的,也是应该的,这样才能造就百年企业。
问题在于“垄断”。
你通过权力手段搞垄断,只许自己家族或团队把持这个行业,在国内你们确实一直赢赢赢,但是长期垄断会导致傲慢的态度、低质的服务和劣质的产品,在国际市场上,你们就会输输输……
不能搞垄断,要给人民选择权,有竞争才会有进步。
V2RayA的安装和配置,见官方文档https://v2raya.org/docs/prologue/introduction/
我的操作系统是Ubuntu 22,安装的V2RayA的版本是2.2.6.2。
V2RayA翻墙节点启动后,我能使用火狐浏览器成功访问到goole.com。
V2RayA翻墙节点启动后,在操作系统后台运行,即使我们重启浏览器或重启操作系统,它依旧是在运行着的。
有时候我们在终端下载安装一些国外的软件包,由于GFW原因,网速非常慢,很久都下载不下来,那么Ubuntu的终端如何使用v2rayA翻墙?
停止V2RayA的翻墙节点后,在终端运行以下命令:
$ wget www.google.com
--2024-11-08 01:25:07-- http://www.google.com/
正在解析主机 www.google.com (www.google.com)... 31.13.94.36, 2001::1
正在连接 www.google.com (www.google.com)|31.13.94.36|:80...发现连不上谷歌。 启动V2RayA的翻墙节点后,再次在终端运行以下命令:
$ wget www.google.com
--2024-11-08 01:27:41-- http://www.google.com/
正在解析主机 www.google.com (www.google.com)... 31.13.94.36, 2001::1
正在连接 www.google.com (www.google.com)|31.13.94.36|:80... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度: 未指定 [text/html]
正在保存至: ‘index.html’
index.html [ <=> ] 21.11K --.-KB/s 用时 0.002s
2024-11-08 01:27:41 (11.7 MB/s) - ‘index.html’ 已保存 [21612]可见,成功连接到谷歌并下载了谷歌的主页到index.html文件!上述实验说明,只要我们成功启动了V2RayA的翻墙节点,Ubuntu的终端也能借助V2RayA进行翻墙!
如果你启动了V2RayA的翻墙节点后,火狐浏览器能成功访问到goole.com,但是在终端运行wget www.google.com命令连不上谷歌,也许你应该在Ubuntu操作系统的设置->网络->网络代理中手动配置代理,如下图所示:
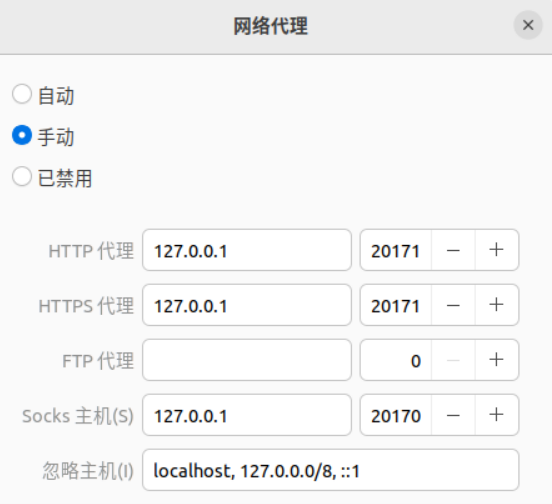
其中20171是V2RayA默认使用的http代理端口,20170是V2RayA默认使用的socks5代理端口。
Overview:newgrp is a command used to change the group associated with the current user. It allows the user to switch to a different group, affecting file permissions and other operations. This command operates within the context of the currently logged-in user, meaning it cannot be used to change the group for other users.
Syntax:
newgrp [group_name]Details:newgrp works similarly to the login command. It allows the user to log in again under the same account but with a different group. The primary effect of running newgrp is that it switches the user’s effective group to the specified one, which will influence operations such as file access permissions.
If no group is specified, newgrp logs the user into the default group associated with the user’s username.
To use newgrp to switch groups, the user must be a member of the specified group. Otherwise, access to that group will be denied. Once a user has switched groups via newgrp, they can revert to their original group by using the exit command to close the current shell session.
Parameters:
Example:
To add a user to the docker group:
$ sudo usermod -aG docker usernameReplace username with the actual username. To add the current user to the docker group, run:
$ sudo usermod -aG docker $USERAfter adding the user to the docker group, a re-login or system restart is required for the changes to take effect. Alternatively, use the following command to reload the user’s group memberships without logging out:
$ newgrp docker功能说明:更改当前用户所属的组。
语 法:newgrp [群组名称]
补充说明:newgrp指令类似login指令,它是以相同的帐号,使用另一个群组名称,再次登入系统。它的作用是将当前用户的有效组切换为指定的组,这样做会影响文件权限等操作,但它只能在当前登录的用户上下文中运行,不能用于切换其他用户的组。欲使用newgrp指令切换群组,你必须是该群组的用户,否则将无法登入指定的群组。若不指定群组名称,则newgrp指令会登入该用户名称的预设群组。一旦你通过 newgrp 切换了组,你可以通过exit命令退出当前 shell 会话来恢复原有的组。
参 数:
群组名称
实 例:
将用户添加到 Docker 组:
$ sudo usermod -aG docker username
你需要将 username 替换为实际的用户名。可以使用以下命令添加当前用户:
$ sudo usermod -aG docker $USER
用户被添加到 docker 组后,需要重新登录或重启系统,才能使更改生效。也可以运行以下命令重新加载用户的组:
$ newgrp docker
Overviewjq is a command-line utility for processing JSON data, similar in functionality to sed and awk but specifically designed for JSON, making it extremely powerful for parsing, filtering, and formatting JSON data.
Usage
jq [options] <jq filter> [file...]
jq [options] --args <jq filter> [strings...]
jq [options] --jsonargs <jq filter> [JSON_TEXTS...]Descriptionjq processes JSON input by applying specified filters to JSON text, outputting the result in JSON format to standard output. The simplest filter is . (dot), which outputs the JSON input as-is (with formatting adjustments and IEEE 754 numeric representation). For more complex filters, refer to the jq(1) manual or jq’s official documentation.
Options
-c: Compresses output, removing whitespace and newlines to produce compact JSON.-r: Outputs raw format without quotes, useful for string values.-R: Reads raw strings instead of JSON text.-s: Slurps all input JSON objects into a single array.-n: Uses null as the input, often used to create new JSON objects without reading input.-e: Sets exit status based on output.-S: Sorts keys in output JSON objects.-C: Colors JSON output (enabled by default).-M: Monochrome mode, disables JSON coloring.--tab: Indents using tabs.--arg a v: Sets $a to value <v>.--argjson a v: Sets shell variable $a to JSON value <v>.--slurpfile a f: Sets $a as an array from JSON data in file <f>.--rawfile a f: Sets $a to the raw content of file <f>.--args: Treats remaining arguments as string parameters, not files.--jsonargs: Treats remaining arguments as JSON parameters.--: Stops processing options.Arguments can also be accessed using $ARGS.named[] for named parameters or $ARGS.positional[] for positional parameters.
Parameters
file...: One or more files.strings...: One or more strings.JSON_TEXTS...: One or more JSON strings.Filters
.: Refers to the current JSON object, used to access fields.[]: Accesses elements in an array.|: Passes output from one expression as input to the next.{}: Creates a new JSON object.[] | .field: Traverses an array and extracts specific fields from each object.Operators and Built-in Functions
Includes common operators (+, -, *, /, %) and functions like length, has, map, select, unique, min, and max. String functions include split, join, startswith, and endswith. Regex and mathematical functions are also available, such as test, match, sqrt, and range.
Examples
1 Basic Examples
Compact JSON output by removing whitespace and newlines:
echo '{"name": "Alice", "age": 30}' | jq -c .Output:{"name":"Alice","age":30}
Raw output without quotes, typically for string values:
echo '{"name": "Alice", "age": 30}' | jq -r .nameOutput:Alice
Combine all input JSON objects into an array:
$ echo '{"name": "Alice", "age": 30}{"name": "Bob", "age": 25}{"name": "Charlie", "age": 35}' | jq -s .Output:
[
{ "name": "Alice", "age": 30 },
{ "name": "Bob", "age": 25 },
{ "name": "Charlie", "age": 35 }
]Passing shell variables to jq as JSON variables:
name="Alice"
echo '{}' | jq --arg name "$name" '{name: $name}'Output:{ "name": "Alice" }
2 Filter Examples
Access an element in a JSON array:
echo '[{"name": "Alice"}, {"name": "Bob"}, {"name": "Charlie"}]' | jq '.[1]'Output:
{ "name": "Bob" }Create a new JSON object with defined key-value pairs:
jq -n '{name: "Alice", age: 30}'Output:
{ "name": "Alice", "age": 30 }Traverse an array and extract a specific field from each object:
echo '[{"name": "Alice"}, {"name": "Bob"}, {"name": "Charlie"}]' | jq '.[].name'Output:
"Alice"
"Bob"
"Charlie"3 Operators, Control Statements, and Built-in Functions
Use conditional expressions to modify output:
echo '[{"name": "Alice", "age": 30}, {"name": "Bob", "age": 25}, {"name": "Charlie", "age": 35}]' | jq 'map(if .name=="Alice" then "yes" else "no" end)'Output:
[ "yes", "no", "no" ]4 jq Scripts
Save complex jq commands in a .jq file and execute them:
Create a file script.jq with:
map(select(.age > 28) | {name: .name, status: (if .age < 35 then "young" else "mature" end)})Run the script:
echo '[{"name": "Alice", "age": 30}, {"name": "Bob", "age": 25}, {"name": "Charlie", "age": 35}]' | jq -f script.jqOutput:
[
{ "name": "Alice", "status": "young" },
{ "name": "Charlie", "status": "mature" }
]Alternatively, save JSON data to a file and filter it:
$ echo '[{"name": "Alice", "age": 30}, {"name": "Bob", "age": 25}, {"name": "Charlie", "age": 35}]'>input.json
$ jq -f script.jq input.jsonOutput:
[
{ "name": "Alice", "status": "young" },
{ "name": "Charlie", "status": "mature" }
]功能说明:jq是一个用于处理JSON数据的命令行工具,可以解析、筛选、格式化JSON数据。与sed、awk工具类似,jq在处理JSON数据方面非常强大。
语 法:
jq [options] <jq filter> [file…]
jq [options] –args <jq filter> [strings…]
jq [options] –jsonargs <jq filter> [JSON_TEXTS…]
补充说明:jq是一个处理 JSON 输入的工具,应用给定的过滤器到其 JSON 文本输入,并将过滤器的结果作为 JSON 输出到标准输出。最简单的过滤器是.符号,它将jq的输入原封不动地复制到输出(除了格式化,注意内部使用 IEEE754 进行数字表示)。有关更高级的过滤器,请参见jq(1)手册页(“man jq”)和/或 https://stedolan.github.io/jq。
选 项:
-c 压缩输出,去除空白和换行符,以便生成紧凑的 JSON 格式,而非美化格式
-r 以原始格式输出,不加引号,通常用于输出字符串值
-R 读取原始字符串,而非 JSON 文本
-s 将所有输入的 JSON 对象合并为一个数组
-n 使用 `null` 作为唯一输入值。也就是不读取输入,通常与其他表达式结合使用,可以用于生成新的 JSON 对象
-e 根据输出设置退出状态码
-S 对输出的对象按键进行排序
-C 为 JSON 上色。jq默认会为输出的JSON数据上色
-M 单色(不为 JSON 上色)
–tab 使用制表符进行缩进
–arg a v 将变量 $a 设置为值<v>
–argjson a v 将shell变量 $a 设置为 JSON 值 <v>
–slurpfile a f 将shell变量 $a 设置为从 <f> 文件读取的 JSON 文本数组
–rawfile a f 将shell变量 $a 设置为由 <f> 文件的内容组成的字符串
–args 剩余参数是字符串参数,而非文件
–jsonargs 剩余参数是 JSON 参数,而非文件
— 终止参数处理
其中,命名参数也可以作为 $ARGS.named[] 使用,而位置参数可以作为 $ARGS.positional[] 使用。
参 数:
file… 一个或多个文件
strings… 一个或多个字符串
JSON_TEXTS… 一个或多个JSON字符串
过 滤 器:
. 表示当前输入的 JSON 对象,可以用来访问字段
[] 用于访问数组中的元素
| 用于将前一个表达式的输出作为下一个表达式的输入
{} 用于创建新的 JSON 对象
[] | .field 用于遍历数组并提取特定字段
运算符和内建函数:
+,-
*,/,%
>, >=, <=, <
and, or, not
==,!=
in
abs
length
utf8bytelength
has(key)
map(f), map_values(f)
path(path_expression)
del(path_expression)
select(boolean_expression)
add
any
all
bsearch(x)
repeat(exp)
while(cond; update)
indices(s)
index(s), rindex(s)
contains(element)
unique, unique_by(path_exp)
min, max, min_by(path_exp), max_by(path_exp)
flatten, flatten(depth)
字符串相关函数
join(str)
split(str)
implode
explode
rtrimstr(str)
ltrimstr(str)
endswith(str)
startswith(str)
reverse
正则表达式相关函数
test(val), test(regex; flags)
match(val), match(regex; flags)
capture(val), capture(regex; flags)
sub(regex; tostring), sub(regex; tostring; flags)
splits(regex), splits(regex; flags)
split(regex; flags)
scan(regex), scan(regex; flags)
gsub(regex; tostring), gsub(regex; tostring; flags)
数学相关函数
sqrt
range(upto), range(from; upto), range(from; upto; by)
floor
更多参考官方文档https://jqlang.github.io/jq/manual/#builtin-operators-and-functions
流程控制语句:
if A then B else C end
try-catch
break
实 例:
1 简单的实例
压缩输出,去除空白和换行符,以便生成紧凑的 JSON 格式:
echo ‘{“name”: “Alice”, “age”: 30}’ | jq -c .
输出:{“name”:”Alice”,”age”:30}
以原始格式输出,不加引号,通常用于输出字符串值:
echo ‘{“name”: “Alice”, “age”: 30}’ | jq -r .name
输出:Alice
将所有输入的 JSON 对象合并为一个数组:
$ echo ‘{“name”: “Alice”, “age”: 30}{“name”: “Bob”, “age”: 25}{“name”: “Charlie”, “age”: 35}’ | jq -s .
输出:
[
{
“name”: “Alice”,
“age”: 30
},
{
“name”: “Bob”,
“age”: 25
},
{
“name”: “Charlie”,
“age”: 35
}
]
将 shell 变量传递给 jq 作为变量
name=”Alice”
echo ‘{}’ | jq –arg name “$name” ‘{name: $name}’
输出:{“name”:”Alice”}
2 过滤器实例
[] 用于访问JSON数组中的元素
echo ‘[{“name”: “Alice”}, {“name”: “Bob”}, {“name”: “Charlie”}]’ | jq ‘.[1]’
输出:
{
“name”: “Bob”
}
在这个例子中,.[1] 访问数组中的第二个元素(索引从0开始)。
{}用于创建新的JSON对象,可以根据需要定义键值对
jq -n ‘{name: “Alice”, age: 30}’
输出:
{
“name”: “Alice”,
“age”: 30
}
这里使用 -n 选项表示不读取输入,而是直接创建一个新的 JSON 对象。
[] | .field用于遍历一个数组并提取每个对象中的特定字段
echo ‘[{“name”: “Alice”}, {“name”: “Bob”}, {“name”: “Charlie”}]’ | jq ‘.[].name’
输出:
“Alice”
“Bob”
“Charlie”
在这个例子中,[].name 遍历数组中的每个对象,提取 name 字段的值。
3 运算符、流程控制语句和内置函数实例
echo ‘[{“name”: “Alice”, “age”: 30}, {“name”: “Bob”, “age”: 25}, {“name”: “Charlie”, “age”: 35}]’ | jq ‘map(if .name==”Alice” then “yes” else “no” end)’
输出:
[
“yes”,
“no”,
“no”
]
4 jq脚本实例
你可以将复杂的 jq 脚本写入一个 .jq 文件,然后在命令行中引用该文件。步骤如下。首先,创建一个名为 script.jq 的文件,并将你的 jq 脚本写入其中:
# script.jq
map(select(.age > 28) | {name: .name, status: (if .age < 35 then “年轻” else “成熟” end)})
然后在命令行中使用 jq 运行这个脚本:
echo ‘[{“name”: “Alice”, “age”: 30}, {“name”: “Bob”, “age”: 25}, {“name”: “Charlie”, “age”: 35}]’ | jq -f script.jq
输出:
[
{
“name”: “Alice”,
“status”: “年轻”
},
{
“name”: “Charlie”,
“status”: “成熟”
}
]
也可以把JSON数据放到一个文件中,再运行jq脚本来过滤它,例如:
$ echo ‘[{“name”: “Alice”, “age”: 30}, {“name”: “Bob”, “age”: 25}, {“name”: “Charlie”, “age”: 35}]’>input.json
$ jq -f script.jq input.json
输出:
[
{
“name”: “Alice”,
“status”: “年轻”
},
{
“name”: “Charlie”,
“status”: “成熟”
}
]
我的Laravel版本是10,报错原因是overtrue/laravel-lang:~6.0与Laravel 10不兼容,composer require “overtrue/laravel-lang”输出一条警告说:
Package overtrue/laravel-lang is abandoned, you should avoid using it.
在Laravel 10我们应该使用laravel-lang/lang语言包。因此这个报错的解决方法是,先移除overtrue/laravel-lang:~6.0包:
composer remove overtrue/laravel-lang
再安装laravel-lang/lang语言包:
composer require laravel-lang/lang
安装好了后,执行以下命令添加中文语言包到Laravel 10:
php artisan lang:add zh_CN
我们可以看到在resources/lang目录里增加了zh_CN.json文件和zh_CN文件夹。
然后修改config/app.php,找到’locale’ => ‘en’,改为’locale’ => ‘zh_CN’。
刷新浏览器看看。
更多laravel-lang/lang语言包的用法,例如如何添加多个语言包到Laravel、如何在“语言.json”文件里增加自定义的条目等,请查看laravel-lang/lang语言包的官方文档:Getting Started | Laravel Lang (laravel-lang.com)
参考
没有必要使用composer国内镜像源,理由如下:
1 国内网络直连composer默认的国外源速度并不慢。
2 composer国内镜像源,例如阿里云的composer镜像源,里面的包的版本更新不及时,案例见composer安装Laravel 11报错:laravel/framework[v11.9.0, …, v11.23.3] require fruitcake/php-cors ^1.3 -> found fruitcake/php-cors[dev-feat-setOptions, dev-master, dev-maincomposer…
Overview
The echo command is used to display strings or variables in the terminal.
Usage
echo [options] [args]Descriptionecho is ideal for outputting text, displaying variables, and creating formatted outputs.
Options
-e: Enables escape characters such as newline \n and tab \t. Common escape sequences include:
\n: Newline\t: Horizontal tab\\: Backslash\": Double quote\a: Alert (beep)\b: Backspace\v: Vertical tab-n: Prevents auto newline at the end of the output. By default, echo will automatically add a newline, which -n can disable.Arguments
args: One or more strings or variables to be printed.Examples
1 Simple Text Output
$ echo "Hello, World!"Output:
Hello, World!
2 Display Variable Values
You can print variable values by prefixing the variable name with $:
$ name="Alice"
$ echo "Hello, $name"Output:
Hello, Alice
To display environment variables:
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
$ echo $HOME
/home/user
$ echo $USER
user3 Using Command Substitution
echo can use command substitution with $(command) to insert the output of a command:
$ echo "Today is $(date)"Output:
Today is Sun Oct 25 10:20:22 AM
4 Multi-line Output
Use the -e option to enable escape characters like \n for multi-line output:
$ echo -e "Line 1\nLine 2\nLine 3"Output:
Line 1
Line 2
Line 35 Suppress Auto Newline
To suppress the newline, use -n:
$ echo -n "Hello, World!"Output:
Hello, World! (without newline)
6 Using Escape Characters
Enable escape characters with -e for features like tabs (\t) and newlines (\n):
$ echo -e "Column1\tColumn2\nData1\tData2"Output:
Column1 Column2
Data1 Data27 Redirect Output to File
Redirect echo output to a file. Use > to overwrite or >> to append:
$ echo "Hello, World!" > output.txt # Overwrite
$ echo "Another Line" >> output.txt # Append8 Output Strings with Special Characters
For special characters (like $, “, ), use single quotes or escape them with \:
$ echo "This is a dollar sign: \$ and a quote: \""Output:
This is a dollar sign: $ and a quote: “