本文翻译自《Arrays, slices (and strings): The mechanics of ‘append’》。
Rob Pike
2013/09/26
介绍
面向过程的编程语言的最常见的特性之一是数组的概念。数组看起来很简单,但在将它们添加到编程语言中时,必须回答许多问题,例如:
- 固定长度还是可变长度?
- 长度是这个类型的一部分吗?
- 多维数组是什么样子的?
- 空数组有意义吗?
这些问题的答案会决定数组是编程语言的一个特性还是其设计的核心部分。
在Go的早期开发中,大约花了一年时间来决定这些问题的答案,然后才觉得设计是正确的。关键的一步是引入切片(slice),它建立在固定大小的数组上,以提供灵活的、可扩展的数据结构。然而,时至今日,刚接触Go的程序员经常会在切片的工作方式上磕磕碰碰,也许是因为其他语言的经验影响了他们的思维。
在这篇文章中,我们将试图消除混乱。我们将通过构建代码片段的方式来解释内置函数append是如何工作的,以及为什么它会这样工作。
数组
数组是Go中的一个重要的组成元素,但与建筑的基础一样,它通常隐藏在更显眼的组件下面。在我们继续讨论切片这个更有趣、更强大、更突出的概念之前,我们必须先简要地讨论一下数组。
数组在Go程序中并不常见,因为数组的大小是其类型的一部分,这限制了它的表达能力。
声明
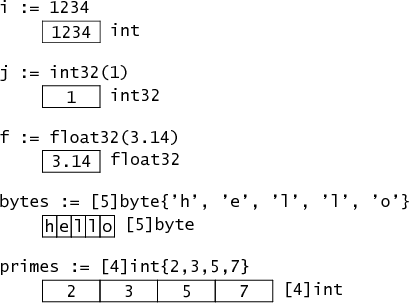
var buffer [256]byte
声明了buffer变量,是一个数组,可容纳256个字节。buffer的类型包括其大小[256]byte。而具有512个字节长度的数组将是不同的类型:[512]byte。
与数组相关联的数据就是数组的元素们。从以下示意图来看,我们的buffer数组在内存中是这样的,
buffer: byte byte byte ... 256 times ... byte byte byte
也就是说,该变量包含256字节的数据。我们可以通过buffer[255]使用熟悉的索引语法:buffer[0]、buffer[1]等来访问它的元素。这里的buffer数组的索引范围是0到255,包含256个元素。试图用超出此范围的值对buffer数组进行索引将导致程序崩溃。
有一个名为len的内置函数,它返回数组或切片以及其他一些数据类型的元素数量。对于数组,len返回的内容是显而易见的。在我们的示例中,len(buffer)返回固定值256。
数组有自己的作用——例如,它们可以很好地表示矩阵——但它们在Go中最常见的用途是作为切片的底层存储。
切片
想使用好切片,必须准确地了解它们是什么以及它们的作用。
切片是一种数据结构,描述与切片变量本身分开存储的数组的连续部分。切片不是数组。切片描述某一个数组的一部分。
对于上一节中的buffer数组,我们可以通过对该数组进行切片来创建元素下标100到150(准确地说,是100到149,包括100到149)的切片:
var slice []byte = buffer[100:150]
在该代码段中,我们使用了显式的完整的变量声明:变量slice的类型为[]byte,发音为“slice of bytes”,通过对buffer数组元素从下标100(包含)到150(不包含)进行切片,来初始化。更惯用的语法是不写出切片的类型:
var slice = buffer[100:150]
在函数体中,我们也可以使用海象运算符来初始化一个切片:
slice := buffer[100:150]
切片变量究竟是什么?虽然这还不是全貌,但现在可以将切片视为一个包含两个元素的小数据结构:长度和指向数组元素的指针。你可以把它想象成是在底层构造的如下所示的结构:
type sliceHeader struct {
Length int
ZerothElement *byte
}
slice := sliceHeader{
Length: 50,
ZerothElement: &buffer[100],
}
当然,这只是一个例子。尽管这个sliceHeader结构对程序员来说是不可见的,并且元素指针的类型取决于元素的类型,但这给出了切片底层机制的一般性概念。
到目前为止,我们已经对数组使用了切片操作,但我们也可以对切片进行切片,如下所示:
slice2 := slice[5:10]
与之前一样,此操作创建一个新的切片,具有原始切片的下标从5到9(包含9)的元素,这意味着这个新切片具有原始数组的下标从105到109的元素。slice2变量的底层sliceHeader结构如下所示:
slice2 := sliceHeader{
Length: 5,
ZerothElement: &buffer[105],
}
请注意,此结构的指针仍然指向存储在buffer变量中的底层数组。
我们也可以重新切片(再切片,reslice),也就是说对切片进行切片:
slice = slice[5:10]
这个slice变量的sliceHeader结构与slice2变量的结构类似。你将经常使用重新切片,例如截断一个切片。以下这行代码截除切片的第一个和最后一个元素:
slice = slice[1:len(slice)-1]
[练习:写出上述赋值后的slice变量的sliceHeader结构的样子。]
你经常会听到有经验的Go程序员谈论“切片头sliceHeader”,因为它实际上是存储在切片变量中的东西。例如,当你调用一个以切片为参数的函数时,例如bytes.IndexRune,切片头就是传递给函数的内容。在以下调用中,
slashPos := bytes.IndexRune(slice, '/')
传递给IndexRune函数的slice参数实际上是一个“切片头”。
切片头中还有一个数据项,我们将在下面讨论,但首先让我们看看当使用切片编程时,切片头的存在意味着什么。
把切片传递给函数
重要的是要理解,即使切片包含指针,它本身也是一个值。在底层,它是一个结构体值,包含一个指针和一个长度,而不是指向某个结构体值的指针。
这很重要。
当我们在前面的例子中调用IndexRune函数时,传递了一个切片头的副本。这种行为具有重要的影响。
考虑一下这个简单的函数:
func AddOneToEachElement(slice []byte) {
for i := range slice {
slice[i]++
}
}
顾名思义,该函数迭代切片的索引(使用for range循环),使其元素的值加1。试试看:
func main() {
slice := buffer[10:20]
for i := 0; i < len(slice); i++ {
slice[i] = byte(i)
}
fmt.Println("before", slice)
AddOneToEachElement(slice)
fmt.Println("after", slice)
}
(如果你想探索,可以编辑并执行上述可运行的代码段。)
即使切片头是按值传递的,它也包含指向数组元素的指针,因此原始切片头和传递给函数的切片头副本都描述了同一个底层数组。因此,当函数返回时,可以通过原始切片头看到被修改后的元素。
函数的切片实参确实是一个副本,如本例所示:
func SubtractOneFromLength(slice []byte) []byte {
slice = slice[0 : len(slice)-1]
return slice
}
func main() {
fmt.Println("Before: len(slice) =", len(slice))
newSlice := SubtractOneFromLength(slice)
fmt.Println("After: len(slice) =", len(slice))
fmt.Println("After: len(newSlice) =", len(newSlice))
}
在这里,我们看到切片参数的内容可以由函数修改,但其切片头不能。存储在切片变量中的长度不会被函数的调用所修改,因为函数传递的是切片头的副本,而不是原始切片头。因此,如果我们想编写一个修改切片头的函数,我们必须将其作为结果参数返回,就像我们在这里所做的那样。slice变量不变,但返回的值具有新的长度,然后将其存储在newSlice中,
切片指针:方法的接收者
让函数修改切片头的一种方法是将指针传递给它。下面是我们前面示例的一个变体:
func PtrSubtractOneFromLength(slicePtr *[]byte) {
slice := *slicePtr
*slicePtr = slice[0 : len(slice)-1]
}
func main() {
fmt.Println("Before: len(slice) =", len(slice))
PtrSubtractOneFromLength(&slice)
fmt.Println("After: len(slice) =", len(slice))
}
这个例子使用了指向切片的指针,但看起来很笨拙。要修改切片,我们通常使用指针接收者。
假设我们有一个方法,在最后一个斜杠处截断切片。我们可以这样写:
type path []byte
func (p *path) TruncateAtFinalSlash() {
i := bytes.LastIndex(*p, []byte("/"))
if i >= 0 {
*p = (*p)[0:i]
}
}
func main() {
pathName := path("/usr/bin/tso") // Conversion from string to path.
pathName.TruncateAtFinalSlash()
fmt.Printf("%s\n", pathName)
}
如果运行此示例,你将看到它能合理地工作,更改函数中的切片。
[练习:将接收者的类型更改为值而不是指针,然后再次运行。解释会发生什么。]
另一方面,如果我们想为path编写一个方法,使path中的ASCII字母大写(简单地忽略非英文字母),则该方法可以传入一个切片值,因为切片值接收者仍将指向相同的底层数组。
type path []byte
func (p path) ToUpper() {
for i, b := range p {
if 'a' <= b && b <= 'z' {
p[i] = b + 'A' - 'a'
}
}
}
func main() {
pathName := path("/usr/bin/tso")
pathName.ToUpper()
fmt.Printf("%s\n", pathName)
}
在这里,ToUpper方法使用for range中的两个迭代变量来捕获slice的下标和元素。
[练习:将ToUpper方法转换为使用指针接收者,并查看其行为是否发生变化。]
[高级练习:改写ToUpper方法以处理Unicode字母,而不仅仅是ASCII。]
容量
看看下面的函数,它将元素是int类型的切片扩展了一个元素:
func Extend(slice []int, element int) []int {
n := len(slice)
slice = slice[0 : n+1]
slice[n] = element
return slice
}
看看切片是如何生长的,直到不能生长为止。
现在是时候讨论切片头的第三个组成部分了:它的容量。除了数组指针和长度之外,切片头还存储其容量:
type sliceHeader struct {
Length int
Capacity int
ZerothElement *byte
}
Capacity字段记录切片的底层数组实际拥有的空间;它是长度Length可以达到的最大值。试图将切片增长到超出其容量的程度将超出底层数组空间的限制,并引发panic。
上面的代码中,我们这么创建切片:
slice := iBuffer[0:0]
它的切片头类似于如下结构:
slice := sliceHeader{
Length: 0,
Capacity: 10,
ZerothElement: &iBuffer[0],
}
Capacity字段等于切片的底层数组的长度,减去切片的第一个元素在数组中的索引(在上述情况下为零)。如果你想查询切片的容量,可以使用Go内置函数cap:
if cap(slice) == len(slice) {
fmt.Println("slice is full!")
}
make
如果我们想让切片超出其容量,该怎么办?你不做不到!根据定义,容量是切片增长的极限。但是,你可以创建一个容量更大的新数组,复制旧切片的数据到这个新数组,然后让旧切片指向这个新数组。
让我们开始创建。我们可以使用内置函数new来分配一个更大的数组,然后对结果进行切片,但使用内置函数make会更简单,它创建一个新数组并创建一个切片头来指向它。函数make接受三个参数:切片的类型、初始长度和容量。容量即make创建的用于保存切片数据的底层数组的长度。以下这个调用创建了一个长度为10的切片,还有5个的额外的空间可以扩展:
slice := make([]int, 10, 15)
fmt.Printf("len: %d, cap: %d\n", len(slice), cap(slice))
以下这个代码片段使int切片的容量增加了一倍,但长度保持不变:
slice := make([]int, 10, 15)
fmt.Printf("len: %d, cap: %d\n", len(slice), cap(slice))
newSlice := make([]int, len(slice), 2*cap(slice))
for i := range slice {
newSlice[i] = slice[i]
}
slice = newSlice
fmt.Printf("len: %d, cap: %d\n", len(slice), cap(slice))
运行此代码后,在需要再次重新分配空间之前,切片已经有更多的增长空间。
在创建切片时,长度和容量通常是相同的。内置函数make对这种常见情况有一个简写。length参数默认等于容量,因此可以省略容量参数,将两者设置为相同的值:
gophers := make([]Gopher, 10)
切片gophers的长度和容量都设置为10。
Copy
当我们在上一节中将切片的容量加倍时,我们编写了一个循环来将旧数据复制到新切片。Go有一个内置函数copy,可以让这变得更容易。它的参数是两个切片,并将数据从右侧参数复制到左侧参数。以下是我们使用copy的示例:
newSlice := make([]int, len(slice), 2*cap(slice))
copy(newSlice, slice)
copy很智能,它只复制它可以复制的内容,并注意两个切片参数的长度。 换句话说,它复制的元素数量是两个切片长度中的小的那个。此外,copy返回一个整数值,即它复制的元素数量,尽管并不总是值得检查这个返回值。
当源切片和目标切片重叠时,copy函数也能正确处理,这意味着它可以用于在单个切片中移动元素。以下示例如何使用copy将值插入切片的中间:
// Insert函数在切片slice指定的下标index处插入元素值value,index不能超出切片slice的下标范围,并且切片slice必须还有额外容量可供插入新元素
func Insert(slice []int, index, value int) []int {
// 先给切片slice扩展一个元素的空间
slice = slice[0 : len(slice)+1]
// 使用copy函数把切片slice的从index下标开始的右半部分元素,往右移动一格位置,以在index处空出一个位置
copy(slice[index+1:], slice[index:])
// 把值value存入index处
slice[index] = value
return slice
}
在这个函数中有几点需要注意。首先,当然,它必须返回更新后的切片,因为它的长度已经改变。其次,它使用了一种方便的简写。表达式:
slice[i:]
与以下表达式等价:
slice[i:len(slice)]
此外,尽管我们还没有使用这个技巧,但我们也可以省略切片表达式的第一个元素;它默认为零。因此:
slice[:]
指切片本身,这在对数组进行切片时很有用。以下这个表达式是创建一个“描述数组所有元素的切片”的最短的表达式:
array[:]
现在,让我们运行Insert函数:
slice := make([]int, 10, 20) // 注意创建的切片的容量要大于长度,才能插入元素
for i := range slice {
slice[i] = i
}
fmt.Println(slice)
slice = Insert(slice, 5, 99)
fmt.Println(slice)
Append函数示例
在前几节中,我们编写了一个Extend函数,该函数将切片扩展一个元素。不过,它有缺陷,因为如果切片的容量太小,该函数就会崩溃。(我们的Insert函数也有同样的问题。)现在我们已经准备好了解决这个问题的代码,所以让我们为整数切片编写一个健壮的Extend实现吧:
func Extend(slice []int, element int) []int {
n := len(slice)
if n == cap(slice) {
// 切片容量满了,必须扩容。在这里把切片的容量变成原来的2倍
newSlice := make([]int, len(slice), 2*len(slice)+1)
copy(newSlice, slice)
slice = newSlice
}
slice = slice[0 : n+1]
slice[n] = element
return slice
}
在这个函数里,尤为重要的是最后要返回切片,因为当源切片被重新分配容量时,得到的切片描述的是一个完全不同的底层数组。以下是一个小片段来演示填充切片时会发生什么:
slice := make([]int, 0, 5)
for i := 0; i < 10; i++ {
slice = Extend(slice, i)
fmt.Printf("len=%d cap=%d slice=%v\n", len(slice), cap(slice), slice)
fmt.Println("address of 0th element:", &slice[0])
}
当大小为5的初始切片被填满时,会重新分配一个底层数组。分配新数组时,第零个元素的地址和数组容量都会发生变化。
有了强大的Extend函数作为指导,我们可以编写一个更好的函数,通过多个元素来扩展切片。为此,我们使用Go的语法,在调用函数时将函数参数列表转换为切片。也就是说,我们使用Go的参数列表长度可变的函数。
让我们调用Append函数。对于第一个版本,我们可以重复调用Extend函数,这样参数列表变长的函数的机制就很清楚了。Append函数的签名如下:
func Append(slice []int, items ...int) []int
这意味着Append函数接受一个参数,即一个切片,然后是零个或多个int参数。就Append的实现而言,这些参数正是int切片的一部分:
// Append函数把items添加到切片slice。
// 第一个版本:仅仅循环调用Extend函数。
func Append(slice []int, items ...int) []int {
for _, item := range items {
slice = Extend(slice, item)
}
return slice
}
请注意,for range循环在items参数的元素上迭代,该参数具有隐含的类型[]int。还要注意使用空白标识符_来丢弃循环中的索引,在这种情况下我们不需要它。
试试看:
slice := []int{0, 1, 2, 3, 4}
fmt.Println(slice)
slice = Append(slice, 5, 6, 7, 8)
fmt.Println(slice)
本例中的另一项新技术是,我们通过编写一个字面量来初始化切片slice,由切片的类型及其大括号中的元素组成:
slice := []int{0, 1, 2, 3, 4}
Append函数之所以有趣,还有一个原因。我们不仅可以附加元素,还可以通过使用…符号来展开一个切片的所有元素:
slice1 := []int{0, 1, 2, 3, 4}
slice2 := []int{55, 66, 77}
fmt.Println(slice1)
slice1 = Append(slice1, slice2...) // ...符号
fmt.Println(slice1)
当然,我们可以在Extend函数的内部,通过不超过一次的分配来提高Append函数的效率:
// 更加高效的Append版本。
func Append(slice []int, elements ...int) []int {
n := len(slice)
total := len(slice) + len(elements)
if total > cap(slice) {
// 重新分配容量为原来的1.5倍
newSize := total*3/2 + 1
newSlice := make([]int, total, newSize)
copy(newSlice, slice)
slice = newSlice
}
slice = slice[:total]
copy(slice[n:], elements)
return slice
}
在这里,请注意我们如何使用copy函数两次,一次是将切片数据移动到新分配的内存,另一次是将要添加的元素复制到切片slice旧数据的末尾。
试试看;行为与以前相同:
slice1 := []int{0, 1, 2, 3, 4}
slice2 := []int{55, 66, 77}
fmt.Println(slice1)
slice1 = Append(slice1, slice2...)
fmt.Println(slice1)
Append内置函数
因此,我们得出了设计append内置函数的动机。它与我们的Append示例完全一样,具有同等的效率,但它适用于任何切片类型。
Go的一个弱点是任何泛型类型的操作都必须由运行时提供。总有一天,这种情况可能会改变,但目前,为了更容易地处理切片,Go提供了一个内置的通用的append函数。它的工作原理与我们的int切片版本相同,但适用于任何切片类型。
请记住,由于切片头总是会被append函数更新,因此需要在调用后保存返回的切片头。事实上,编译器不允许在不保存结果的情况下调用append函数。
// 创建两个切片
slice := []int{1, 2, 3}
slice2 := []int{55, 66, 77}
fmt.Println("Start slice: ", slice)
fmt.Println("Start slice2:", slice2)
// 添加元素到切片
slice = append(slice, 4)
fmt.Println("Add one item:", slice)
// 添加一个切片里的所有元素到另一个切片
slice = append(slice, slice2...)
fmt.Println("Add one slice:", slice)
// 复制一个切片,然后赋值给另一个切片
slice3 := append([]int(nil), slice...)
fmt.Println("Copy a slice:", slice3)
// 复制一个切片里的所有元素,然后追加到这个切片的尾部
fmt.Println("Before append to self:", slice)
slice = append(slice, slice...)
fmt.Println("After append to self:", slice)
值得花点时间详细思考以上代码的最后三行。
在社区构建的“Slice Tricks”Wiki页面上,还有更多关于函数append、copy和其他使用切片的方法的示例。
Nil
根据我们新学到的知识,我们可以知道nil切片是什么。自然,它是切片头的零值(zero value):
sliceHeader{
Length: 0,
Capacity: 0,
ZerothElement: nil,
}
或者仅是:
sliceHeader{}
关键细节是其指向底层数组元素的指针也是nil。由一下代码创建的切片:
array[0:0]
长度是0,也许容量也是0,但是其指向底层数组元素的指针不是nil,因此它不是nil切片。
应该清楚的是,空(empty)切片可以增长(假设它具有非零容量),但nil切片没有可放入值的数组,并且永远不能增长到容纳哪怕一个元素。
也就是说,nil切片在功能上等同于零长度的切片,即使它什么都不指向。它的长度为零,但可以被append函数使用。举个例子,看看上面的那一行代码,通过附加到一个nil切片来复制一个切片。
String
现在简要介绍一下Go中的与切片相关的字符串。
字符串实际上非常简单:它们只是只读的字节片,再加上Go语言提供了一些额外的语法支持。
因为它们是只读的,所以不需要容量(不能增长它们),但在其他方面,对于大多数目的,你可以将它们视为只读的字节片。 对于初学者,我们可以对它们进行索引以访问单个字节:
slash := "/usr/ken"[0] // 返回'/'
我们可以通过切片一个字符串来获取它的子串:
usr := "/usr/ken"[0:4] // 返回字符串"/usr"
现在,当我们切片一个字符串时,幕后发生的事情应该很明显了。
我们还可以从一个普通的字节切片,通过简单的强制类型转换从中创建一个字符串:
str := string(slice)
反过来也一样:
slice := []byte(usr)
字符串下面的数组在视图中是隐藏的;除了通过字符串之外,无法访问其内容。这意味着,当我们进行这两种转换时,必须制作数组的一个副本。Go当然会处理好这一点,所以你不必自己这么做。在这两种转换之后,对字节片底层的数组的修改就不会影响相应的字符串。
这种类似切片的字符串设计的一个重要结果是,创建子字符串非常高效。所需要做的就是创建一个字符串头。由于字符串是只读的,原始字符串和切片操作产生的字符串可以安全地共享同一个底层数组。
在Go的早期版本,字符串的最早实现是总会被分配一个底层数组,但当切片被添加到Go中时,它们提供了一个高效的字符串处理的模型。因此,在一些性能测试里表现出了巨大的加速。
当然,字符串还有很多内容可讲,另外一篇博客文章《Go中的字符串,字节,rune和字符(character)》对它进行了更深入的介绍。
结论
要了解切片是如何工作的,了解它们是如何实现的会有所帮助。有一个小数据结构,即切片头。当我们四处传递切片值时,切片头会被复制,但它指向的底层数组总是共享的。
一旦你了解了它们的工作原理,切片不仅易于使用,而且功能强大且富有表现力,尤其是在copy和append内置函数的帮助下。
更多切片相关文章
关于Go中的切片,还有很多值得学习的文章。如前所述,Wiki页面“Slice Tricks”有许多示例。Go Slices博客文章用清晰的图表描述了内存布局的细节。Russ Cox的《Go切片(slice):用法和内部结构》文章包括了对切片的讨论以及Go的一些其他内部数据结构。
还有更多的资料,但了解切片的最好方法是使用它们。











{kind=link}