本文翻译自《Tutorial: Find and fix vulnerable dependencies with govulncheck》。
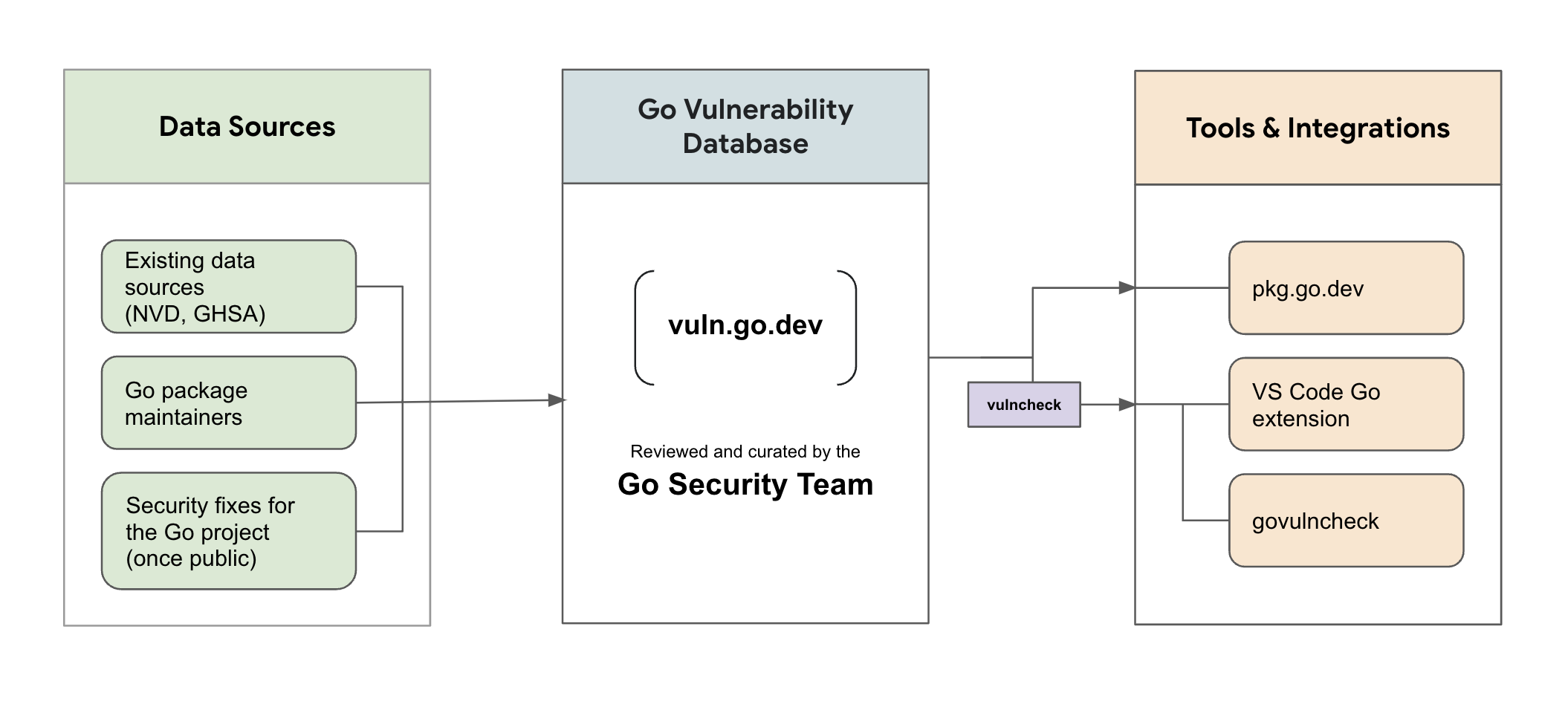
Govulncheck是一个低噪音的工具,可以帮助你发现并修复Go项目中易受攻击的依赖项。它通过扫描项目的依赖项以查找已知的漏洞,并识别出对这些漏洞的任何直接或间接调用的项目代码。
在本教程中,你将学习如何使用govulcheck扫描一个简单的程序以查找漏洞,如何对漏洞进行优先级排序和评估,以便首先集中精力修复最重要的漏洞。
要了解更多关于govulcheck的信息,请参阅govulceck文档和这篇关于Go漏洞管理的博客文章。我们也很乐意听取你的反馈。
先决条件
- 使用Go 1.18或更高版本。Govulncheck旨在与Go 1.18及以后的版本配合使用。我们建议使用最新版本的Go来遵循本教程。(有关安装Go的说明,请参阅安装Go。)
- 一个代码编辑器。任何文本编辑都可以很好地工作。
- 一个命令终端。Go在Linux和Mac的终端程序,以及Windows中的PowerShell或cmd上都能很好地工作。
本教程将带你完成以下步骤:
1 创建一个Go模块示例,它的某个依赖项有漏洞
2 安装并运行govulcheck
3 评估漏洞 4 升级并修复有漏洞的依赖项
创建一个Go模块示例
步骤1,首先,创建一个名为vulntutorial的新文件夹并初始化Go模块。例如,从当前目录运行以下命令:
$ mkdir vuln-tutorial
$ cd vuln-tutorial
$ go mod init vuln.tutorial
步骤2,在vuln-tutorial文件夹中创建一个名为main.go的文件,并将以下代码复制到其中:
package main
import (
"fmt"
"os"
"golang.org/x/text/language"
)
func main() {
for _, arg := range os.Args[1:] {
tag, err := language.Parse(arg)
if err != nil {
fmt.Printf("%s: error: %v\n", arg, err)
} else if tag == language.Und {
fmt.Printf("%s: undefined\n", arg)
} else {
fmt.Printf("%s: tag %s\n", arg, tag)
}
}
}
此示例程序将语言标签的一个列表作为命令行参数,并为每个标签打印一条消息,指示标签是否解析成功、是否未定义或者解析标签时是否出错。
步骤3,运行go mod tidy命令,把main.go的代码所需的所有依赖项记录到go.mod文件。在vuln-tutorial文件夹所在目录,运行以下命令:
$ go mod tidy
你应该能看到类似如下输出:
go: finding module for package golang.org/x/text/language
go: downloading golang.org/x/text v0.9.0
go: found golang.org/x/text/language in golang.org/x/text v0.9.0
第4步,打开go.mod文件,它的内容应该如下所示:
module vuln.tutorial
go 1.20
require golang.org/x/text v0.9.0
第5步,降级golang.org/x/text依赖项的版本到v0.3.5,这个版本包含一个众所周知的安全漏洞:
$ go get golang.org/x/[email protected]
你应该能看到类似如下输出:
go: downgraded golang.org/x/text v0.9.0 => v0.3.5
打开go.mod文件,它的内容应该如下所示:
module vuln.tutorial
go 1.20
require golang.org/x/text v0.3.5
接下来我们使用govulncheck来发现vuln-tutorial项目中的安全漏洞。
安装并运行govulncheck
第6步,使用go install命令安装govulncheck:
$ go install golang.org/x/vuln/cmd/govulncheck@latest
第7步,在vuln-tutorial目录里运行govulncheck来分析vuln-tutorial项目中的安全漏洞:
$ govulncheck ./...
你应该会看到如下输出:
govulncheck is an experimental tool. Share feedback at https://go.dev/s/govulncheck-feedback.
Using go1.20.3 and [email protected] with
vulnerability data from https://vuln.go.dev (last modified 2023-04-18 21:32:26 +0000 UTC).
Scanning your code and 46 packages across 1 dependent module for known vulnerabilities...
Your code is affected by 1 vulnerability from 1 module.
Vulnerability #1: GO-2021-0113
Due to improper index calculation, an incorrectly formatted
language tag can cause Parse to panic via an out of bounds read.
If Parse is used to process untrusted user inputs, this may be
used as a vector for a denial of service attack.
More info: https://pkg.go.dev/vuln/GO-2021-0113
Module: golang.org/x/text
Found in: golang.org/x/[email protected]
Fixed in: golang.org/x/[email protected]
Call stacks in your code:
main.go:12:29: vuln.tutorial.main calls golang.org/x/text/language.Parse
=== Informational ===
Found 1 vulnerability in packages that you import, but there are no call
stacks leading to the use of this vulnerability. You may not need to
take any action. See https://pkg.go.dev/golang.org/x/vuln/cmd/govulncheck
for details.
Vulnerability #1: GO-2022-1059
An attacker may cause a denial of service by crafting an
Accept-Language header which ParseAcceptLanguage will take
significant time to parse.
More info: https://pkg.go.dev/vuln/GO-2022-1059
Found in: golang.org/x/[email protected]
Fixed in: golang.org/x/[email protected]
解释一下上述输出
注意,不同Go版本,上述输出可能不同。
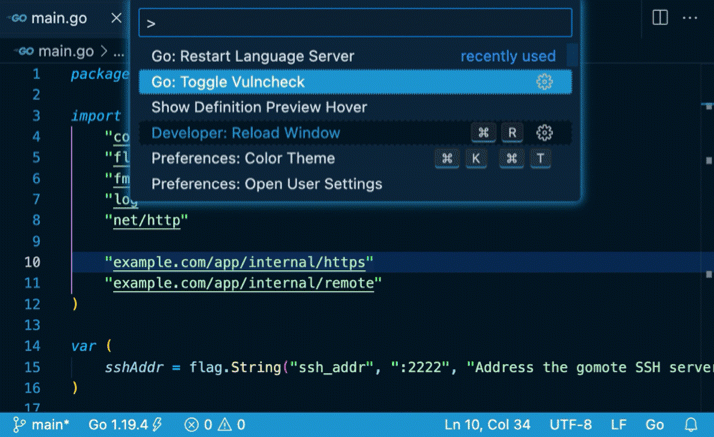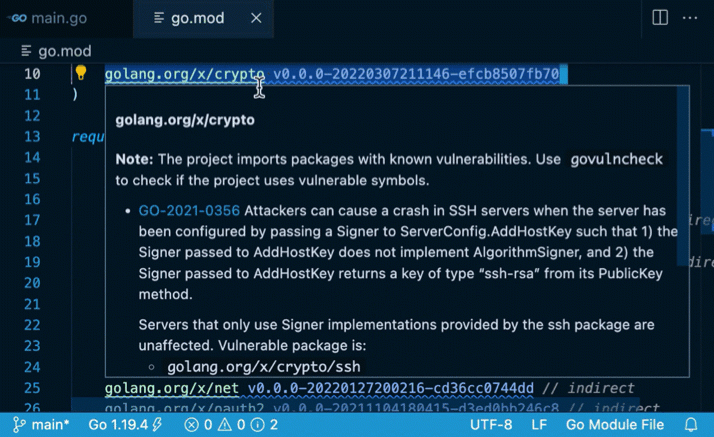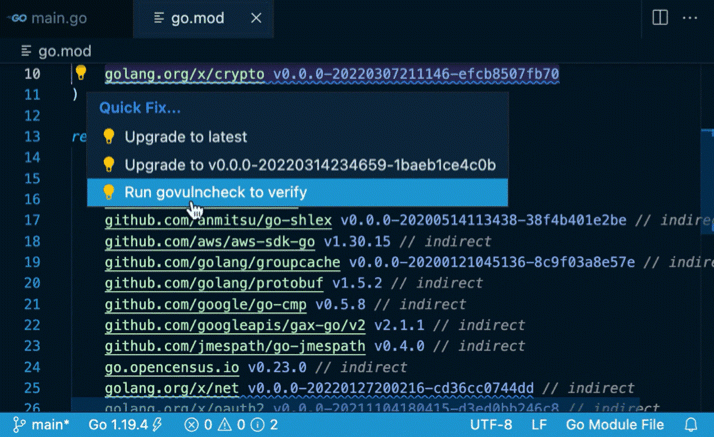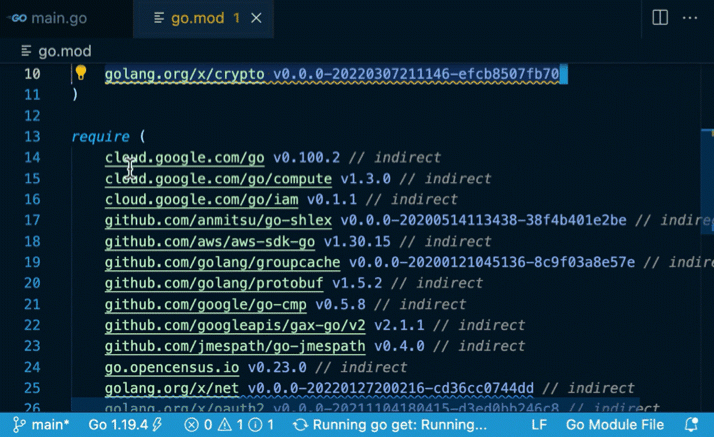
我们的代码受到漏洞GO-2021-0113的影响,因为它直接调用golang.org/x/text/language的Parse函数,而这个函数在v0.3.5版本存在安全漏洞。
golang.org/x/text模块v0.3.5中存在另一个漏洞GO-2022-1059。然而,它被报告为“Informational”,因为我们的代码没有(直接或间接)调用这个安全漏洞相关的函数。
现在,让我们评估vuln-tutorial项目中的漏洞并确定要采取的行动。
评估漏洞
a.评估漏洞
首先,阅读漏洞的描述信息,并确定它是否真的适用于你的代码和用例。如果你需要更多信息,请访问“More info”链接。
根据描述,漏洞GO-2021-0113在使用Parse函数处理不受信任的用户输入时可能会引发panic。假设我们打算让我们的程序承受不受信任的输入,那么该漏洞可能就会被利用。
漏洞GO-2022-1059不会影响我们的代码,因为我们的代码没有从该依赖项中调用任何有安全漏洞的函数。
b.决定采取什么行动
为了解决GO-2021-0113漏洞问题,我们有以下几个选择:
选项1:升级到修复后的版本。如果有可用的修复,我们可以通过升级到该模块的修复版本来删除安全漏洞。
选项2:停止使用有安全漏洞的标识符。我们可以删除代码中对有安全漏洞的函数的所有调用。但我们需要找到一个替代方案,或者自己实现相关函数。
在本例情况下,我们可以使用修复后的版本,Parse函数是我们程序不可或缺的一部分。让我们将依赖项升级到“fixed in”版本v0.3.7。
漏洞GO-2022-1059与漏洞GO-2021-0113在同一模块中,而且它的修复版本是v0.3.8,所以我们可以通过升级到v0.3.8轻松地同时删除这两个漏洞。
升级并修复有安全漏洞的依赖项
幸运的是,升级并修复有安全漏洞的依赖项非常简单。
第8步,升级golang.org/x/text至v0.3.8版本:
$ go get golang.org/x/[email protected]
你应该能看到如下输出:
go: upgraded golang.org/x/text v0.3.5 => v0.3.8
请注意,我们也可以选择升级到最新版本,或v0.3.8之后的任何其他版本。
第9步,现在再次运行govulcheck:
$ govulncheck ./...
你现在会看到如下输出:
govulncheck is an experimental tool. Share feedback at https://go.dev/s/govulncheck-feedback.
Using go1.20.3 and [email protected] with
vulnerability data from https://vuln.go.dev (last modified 2023-04-06 19:19:26 +0000 UTC).
Scanning your code and 46 packages across 1 dependent module for known vulnerabilities...
No vulnerabilities found.
govuncheck确认没有发现漏洞。
使用命令govulcheck定期扫描依赖项,你可以识别、排序和解决安全漏洞来保护你的项目代码。