本文翻译自《Managing dependencies》。
目录
使用和管理依赖项的工作流程
管理模块依赖项
查找和导入有用的包
在代码中启用依赖项跟踪
给一个模块命名
添加一个依赖项
获取一个指定版本的依赖项
发现可用的更新
升级或降级一个依赖项
同步你代码的依赖项
开发和测试未发布的模块代码
需求某个本地目录中的模块代码
需求来自你自己的代码仓库分支的外部模块代码
使用代码仓库标识符获取特定的某个提交(commit)
移除一个依赖项指定一个模块代理服务器
当你的代码使用外部包时,这些包(作为模块分发)成为依赖项。随着时间的推移,你可能需要升级或更换它们。Go提供了依赖项管理工具,可帮助你在合并外部依赖项时确保Go应用程序的安全。
本主题描述如何执行任务来管理你在代码中采用的依赖项。你可以使用Go工具执行其中的大部分操作。本主题还描述了如何执行一些你可能会觉得有用的其他依赖相关的任务。
另请参阅
- 如果你不熟悉将依赖项作为模块来使用,请查看入门教程以获取简要介绍。
- 使用go命令管理依赖项有助于确保你对依赖项的需求保持一致,并且go.mod文件的内容有效。有关命令的参考,请参阅go命令。你还可以通过键入go help 命令名从命令行获得帮助,例如go help mod tidy。
- 用于更改依赖项的Go命令编辑你的go.mod文件。有关该文件内容的更多信息,请参阅go.mod文件参考。
- 让你的编辑器或IDE能够感知Go模块可以使管理它们的工作变得更容易。有关支持Go的编辑器的更多信息,请参阅编辑器插件和IDE。
- 本主题不描述如何开发、发布和模块的版本控制供其他人使用。有关更多信息,请参阅开发和发布模块。
使用和管理依赖项的工作流程
你可以通过Go工具获取和使用有用的包。在pkg.go.dev上,你可以搜索你可能觉得有用的包,然后使用go命令将这些包导入到你自己的代码中以调用它们的功。
下面列出了最常见的依赖管理步骤。有关每个步骤的更多信息,请参阅本主题中的对应小节。
1 在pkg.go.dev上找到有用的包。
2 在代码中导入所需的包。
3 将你的代码添加到模块中以进行依赖跟踪(如果它不在模块中的话)。请参阅启用依赖项跟踪。
4 添加外部包作为依赖项,以便你可以管理它们。
5 随着时间的推移,根据需要升级或降级依赖项的版本。
管理模块依赖项
在Go中,你将依赖项作为模块来管理,在代码中导入这些模块的包。该过程得到以下支持:
- 用于发布模块和检索其代码的去中心化系统。开发人员使他们的模块可供其他开发人员从代码仓库中使用,并使用版本号发布。开发人员使用版本号在代码仓库中发布他们的模块,供其他开发人员获取并使用。
- 一个包搜索引擎和文档浏览器(pkg.go.dev),你可以在其中找到模块。请参阅查找和导入有用的包。
- 模块版本编号规约可帮助你了解模块的稳定性和向后兼容性。请参阅模块版本编号。
- 使你更容易管理依赖项的Go工具,包括获取模块的源代码、升级等。有关更多信息,请参阅本主题中的各个小节。
查找和导入有用的包
你可以搜索pkg.go.dev来查找包含可能有用的函数的包。
找到要在代码中使用的包后,在页面顶部找到包路径,然后单击复制路径按钮将路径复制到剪贴板。在你自己的代码中,将路径粘贴到import语句中,如下例所示:
import "rsc.io/quote"
在代码导入包后,启用依赖项跟踪并获取要编译的包代码。有关更多信息,请参阅在代码中启用依赖项跟踪和添加依一个赖项。
在代码中启用依赖项跟踪
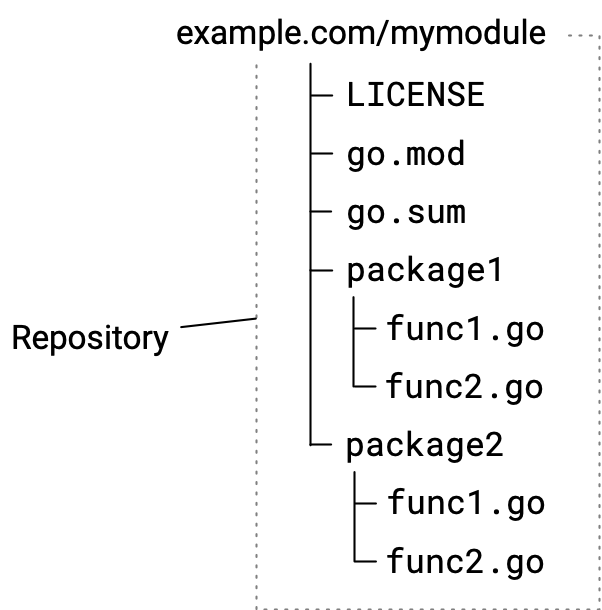
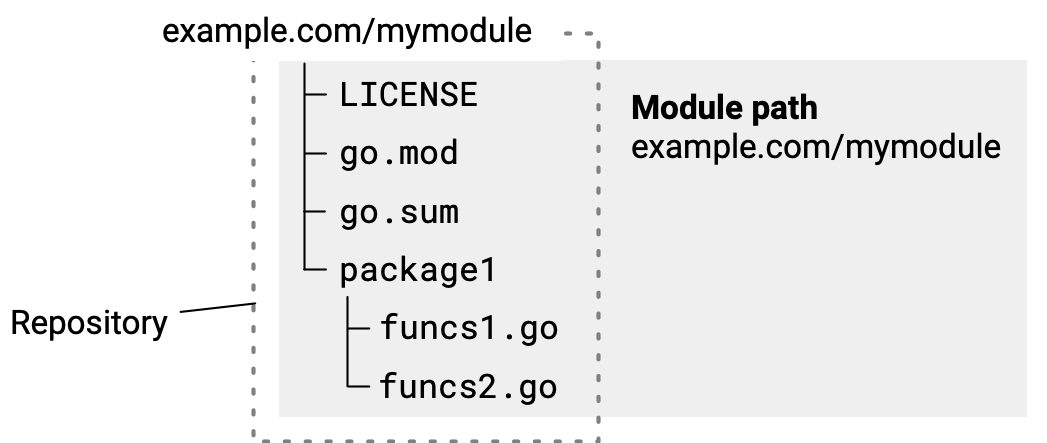
要跟踪和管理你添加的依赖项,你首先要将代码放入其自己的模块中。这会在源代码树的根目录下创建一个go.mod文件。你添加的依赖项将列在该文件中。 要将你的代码添加到它自己的模块中,请使用go mod init命令。例如,从命令行切换到代码的根目录,然后按以下示例运行命令:
$ go mod init example/mymodule
go mod init命令的参数是模块的模块路径。如果可能,模块路径应该是源代码的存储库的位置。
如果一开始你不知道模块的最终存储库位置,请使用一个安全的替代品。这可以是你拥有的域名或你控制的其他名称(如公司名称),以及模块名称或源代码目录的路径。有关详细信息,请参见给一模块个命名。
当你使用Go工具管理依赖关系时,这些工具会更新go.mod文件,以便它维护你当前的依赖项列表。
添加依赖项时,Go工具也会创建一个go.sum文件,其中包含你所依赖的模块的校验和。Go使用该文件来验证下载的模块文件的完整性,尤其是对其他项目开发人员而言。
把go.mod文件和go.sum文件和代码一起放在代码存储库中。
有关更多信息,请参阅go.mod参考手册。
给一个模块命名
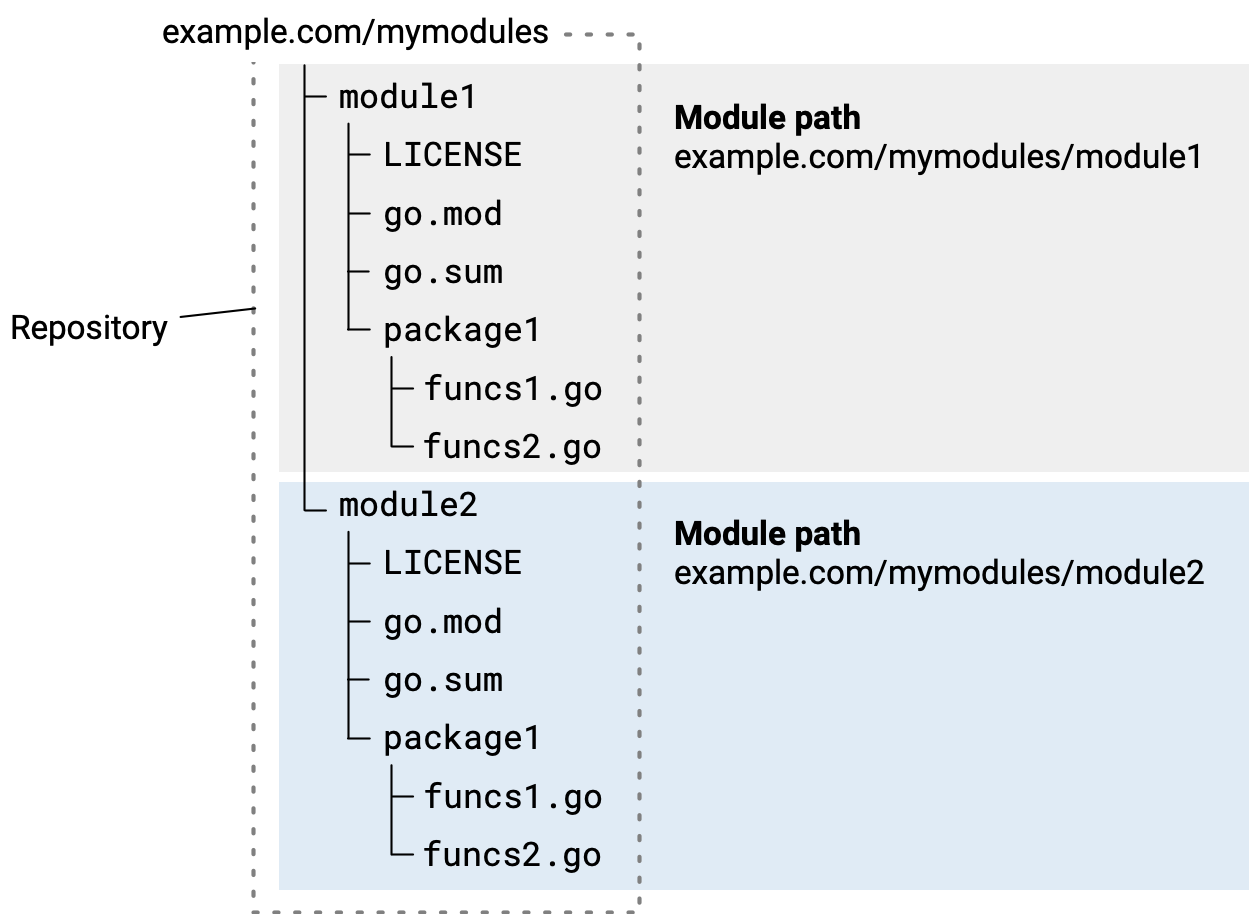
当你运行go mod init以创建用于跟踪依赖项的模块时,你指定一个模块路径作为模块的名称。模块路径是模块中的包的导入路径的前缀。请务必指定一个不会与其他模块的模块路径有冲突的模块路径。
模块路径至少要指出有关其来源的信息,例如公司名称或作者名称或所有者姓名。但是模块路径最好也能描述模块是什么或做什么。 模块路径通常采用以下形式:
<prefix>/<descriptive-text>
前缀prefix通常是部分描述模块的字符串,例如描述模块来源的字符串。这可能是:
- 可以让Go工具找到模块源代码的存储库的位置(如果你要发布模块,则需要模块源代码的存储库)。例如它可能是
github.com/<project-name>/。如果你认为可以发布模块供其他人使用,请使用此最佳实践。有关发布的详细信息,请参阅开发和发布模块。
- 一个你掌控的名字。如果你不使用存储库名称,请确保选择一个你确信不会被其他人使用的前缀。一个很好的选择是你公司的名字。避免使用widgets、utilities或app等常用术语。
对于描述性文本descriptive-text,最好选择项目名称。请记住,包的名称才是主要描述功能信息的。模块路径为这些包的名称创建了一个命名空间。
保留的模块路径前缀
Go保证不会在包名中使用以下字符串。
- test–你可以使用test作为模块的模块路径前缀,该模块的代码旨在本地测试另一个模块中的功能。对作为测试的一部分创建的模块使用test路径前缀。例如,你的测试本身可能会运行
go mod init test,然后以某种特定方式安装该模块,以便使用Go源代码分析工具进行测试。
- example–在某些Go文档中用作模块路径前缀,例如在教程中创建的模块只是为了跟踪依赖项。
请注意,当示例可能是一个已发布的模块时,Go文档也会使用example.com来演示。
添加一个依赖项
从已发布的模块导入包后,可以使用go get命令将该模块添加为依赖项进行管理。
该命令执行以下操作:
- 如果有必要,它会在你的go.mod文件中为命令行上给出的包的模块添加require指令。require指令跟踪所依赖的模块的最低版本。请参阅go.mod参考手册以了解更多信息。
- 如果需要,它会下载模块源代码,以便你可以编译依赖于它们的包。它可以从proxy.golang.org等模块代理或直接从版本控制存储库下载模块。模块源代码缓存在本地。你可以设置Go工具下载模块的位置。有关更多信息,请参阅指定模块代理服务器。
下面描述几个例子。
- 要在模块中添加包的所有依赖项,请运行如下命令(“.”指的是当前目录中的包):
$ go get .
- 要添加特定的依赖项,请将其模块路径指定为该命令的参数:
$ go get example.com/theirmodule
该命令还验证它下载的每个模块。这确保它在模块发布后没有发生改变。如果模块在发布后发生了变化——例如,开发人员更改了提交(commit)的内容——Go工具将显示一个安全错误。此身份验证检查可保护你免受可能已被篡改的模块的侵害。
获取一个指定版本的依赖项
你可以通过在go get命令中指定版本号来获取依赖模块的特定版本。该命令更新go.mod文件中的require指令(当然你也可以手动更新)。
你可能想要那样做,如果:
- 你想要获得模块的指定预发布版本以进行试用。
- 你发现你当前使用的版本不适合你,因此你想获得一个你知道的可以依赖的版本。
- 你想要升级或降级你已经依赖的模块。
以下是使用go get命令的示例:
- 要获取最新版本,请在模块路径后附加@latest:
$ go get example.com/theirmodule@latest
以下go.mod文件的require指令示例(有关更多信息,请参阅go.mod参考手册)说明了如何需求特定版本号:
require example.com/theirmodule v1.3.4
发现可用的更新
你可以检查当前模块中是否已经使用了更新版本的依赖项。使用go list命令显示模块的依赖项列表,以及该模块可用的最新版本。发现可用的升级后,你可以使用你的代码进行试用,以决定是否升级到新版本。
有关go list命令的更多信息,请参阅go list -m。
这里有几个例子。
- 列出当前模块依赖的所有模块,以及每个模块可用的最新版本:
$ go list -m -u all
- 显示特定模块最新可用的版本:
$ go list -m -u example.com/theirmodule
升级或降级一个依赖项
你可以通过使用Go工具发现可用版本来升级或降级依赖的模块,然后将不同的版本添加为依赖项。
1 要发现新版本,请使用go list命令,如发现可用更新小节所述。
2 要将特定版本添加为依赖项,请使用获取一个指定版本的依赖项小节所述的go get命令。
同步你代码的依赖项
你可以管理所有导入的包对应的依赖项,同时删除不再使用的依赖项。
当你一直在更改代码和依赖项时,这可能很有用,可能会创建一个你管理的依赖项和下载模块的集合,这些模块不再与代码中导入的包依赖的模块集合相匹配。
要保持依赖项集合整洁,请使用go mod tidy命令。对于代码中导入的包集,此命令编辑你的go.mod文件以添加必需但缺少的模块。它还会删除不提供任何相关包的未使用的模块。
该命令除了一个标志-v外没有其他参数,它打印有关已删除模块的信息。
$ go mod tidy
开发和测试未发布的模块的代码
你可以指定你的代码使用可能还未发布的依赖项模块。这些模块的代码可能在它们各自的存储库中,在这些存储库的分支中,或者在当前依赖它们的模块所在的本地硬盘里。
你可能希望在以下情况下执行此操作:
- 你想对外部模块的代码进行自己的更改,例如在分叉和/或克隆它之后。例如,你可能想要修复该模块,然后将其作为一个拉取请求(pull request)发送给模块的开发人员。
- 你正在构建一个新模块并且尚未发布它,因此
go get命令访问不到它所在的存储库。
需求本地目录中的某个模块的代码
你可以指定所需模块的代码与依赖它的代码位于同一本地硬盘里。当你处于以下情况时,你可能会发现这很有用:
- 开发自己的独立模块并希望使用当前模块进行测试。
- 修复外部模块中的问题或向外部模块添加功能,并希望使用当前模块进行测试。(请注意,你还可以从你自己的存储库分支中获取外部模块。有关更多信息,请参阅下文的需求来自你自己的代码仓库分支的外部模块代码。)
要让Go命令使用模块代码的本地副本,请在go.mod文件中使用replace指令替换require指令中给出的模块路径。有关指令的更多信息,请参阅go.mod参考手册。
在下面的go.mod文件示例中,当前模块依赖外部模块example.com/theirmodule,使用不存在的版本号(v0.0.0-unpublished)来确保替换正常工作。replace指令然后用../theirmodule替换原始模块路径,该目录与当前模块目录处于同一级别。
module example.com/mymodule
go 1.16
require example.com/theirmodule v0.0.0-unpublished
replace example.com/theirmodule v0.0.0-unpublished => ../theirmodule
设置require/replace对时,使用go mod edit和go get命令确保文件描述的依赖项保持一致:
$ go mod edit -replace=example.com/[email protected]=../theirmodule
$ go get example.com/[email protected]
注意:当你使用replace指令时,Go工具不会验证外部模块,如添加一个依赖项小节所述。
有关版本号的更多信息,请参阅模块版本编号。
需求来自你自己的代码仓库分支的外部模块的代码
当你fork一个外部模块的代码仓库时(例如修复模块代码中的问题或添加新功能),你可以让Go工具使用你fork的代码作为模块的源代码。这对于测试你自己的代码的更改很有用。(请注意,你还可以在本地硬盘目录中需求模块代码。有关更多信息,请参阅需求本地目录中的某个模块的代码小节。)
为此,你可以在go.mod文件中使用replace指令,将外部模块的原始模块路径替换为你fork的代码仓库的路径。这会指示Go工具在编译时使用替换路径(fork的代码仓库的路径),同时允许你保持你代码里的import语句里的原始模块路径保持不变。
有关replace指令的更多信息,请参阅go.mod文件参考手册。
在下面的go.mod文件示例中,当前模块需求外部模块example.com/theirmodule。然后replace指令使用example.com/myfork/theirmodule替换原始模块路径,这是模块代码仓库的你的一个分支。
module example.com/mymodule
go 1.16
require example.com/theirmodule v1.2.3
replace example.com/theirmodule v1.2.3 => example.com/myfork/theirmodule v1.2.3-fixed
设置require/replace对时,最好使用Go工具命令,以确保与go.mod文件中描述的需求保持一致。使用go list命令查看当前使用的模块的版本。然后使用go mod edit命令用fork的分支替换所需的模块:
$ go list -m example.com/theirmodule
example.com/theirmodule v1.2.3
$ go mod edit -replace=example.com/[email protected]=example.com/myfork/[email protected]
注意:当你使用replace指令时,Go工具不会对外部模块进行身份验证,如添加一个依赖项小节中所述。
有关版本号的更多信息,请参阅模块版本编号。
使用代码仓库标识符获取特定的某个提交(commit)
你可以使用go get命令从某个模块的代码仓库中,提取指定某个commit里的未发布(译者注:未加版本号标签)的代码。
为此,你可以使用go get命令,并使用@符号指定你想要的代码。当你使用go get时,该命令将向你的go.mod文件添加一个需求外部模块的require指令,使用基于commit的详细信息的伪版本号。
以下示例提供了一些说明。这些基于一个模块,其源代码位于git存储库中。
- 要提取指定某个commit里的模块代码,请附加
@commithash(译者注:@commit的哈希值)形式:$ go get example.com/theirmodule@4cf76c2
- 要提取指定某个分支里的模块代码,请附加
@branchname(译者注:@分支名称)形式:$ go get example.com/theirmodule@bugfixes
移除一个依赖项
当你的代码不再使用某个模块中的任何包时,你可以停止将该模块作为依赖项进行追踪。
要停止追踪所有未使用的模块,请运行go mod tidy命令。此命令还可以在构建模块的包时添加所需的缺失依赖项。
$ go mod tidy
要删除特定依赖项,请使用go get命令,指定该模块的模块路径并附加@none,如下例所示:
$ go get example.com/theirmodule@none
go get命令还将降级或删除依赖于已删除模块的其他依赖项。
指定一个模块代理服务器
当你使用Go工具处理模块时,这些工具默认从proxy.golang.org(Google运营的公共模块镜像)或直接从模块的代码仓库下载模块。你可以指定Go工具使用另一个代理服务器来下载和验证模块。例如,一些人设置了一个自己的模块代理服务器,以便更好地控制依赖项的使用方式。
要指定另外的模块代理服务器供Go工具使用,请将GOPROXY环境变量设置为一个或多个另外的模块代理服务器的URL。Go工具将按照你指定的顺序尝试每个URL。默认情况下,GOPROXY首先指定一个Google运营的公共的模块代理,然后直接从模块的存储库中下载模块代码(由其模块路径指出):
GOPROXY="https://proxy.golang.org,direct"
有关GOPROXY环境变量(包括其值支持的他行为)的详细信息,请参阅go命令参考手册。
你可以将变量设置为其他模块代理服务器的URL,用逗号或管道分隔多个URL。
- 当你使用逗号时,只有当前URL返回HTTP 404或410时,Go工具才会尝试列表中的下一个URL。
GOPROXY="https://proxy.example.com,https://proxy2.example.com"
- 当你使用管道时,Go工具将尝试列表中的下一个URL,而不考虑HTTP错误代码。
GOPROXY="https://proxy.example.com|https://proxy2.example.com"
Go模块经常在版本控制服务器和模块代理上开发和分发,有些服务器和代理在公共互联网上不可用。此时你可以设置GOPRIVATE环境变量来配置go命令,以便从私有源下载和构建模块。
GOPRIVATE或GONOPROXY环境变量可以设置为与模块前缀匹配的全局模式列表,与这些模式匹配的模块是私有的,不应该从中代理任何请求。例如:
GOPRIVATE=*.corp.example.com,*.research.example.com