
本文翻译自《Go Data Structures》。
2009/11/24
在向新程序员解释Go程序时,我发现解释Go值在内存中的样子通常有助于建立正确的直觉,了解哪些操作是昂贵的,哪些不昂贵。这篇文章是关于Go的基本类型、结构体、数组和切片的。
基本类型
让我们从一些简单的例子开始:
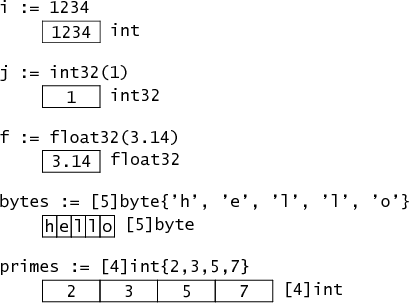
变量i的类型为int,在内存中表示为一个32位的字(word)。(所有这些图片都显示了32位内存布局;在当前的实现中,只有指针在64位机器上变长了——int仍然是32位——尽管可以选择使用64位的int64类型。)
由于显式转换,变量j的类型为int32。即使i和j有相同的内存布局,它们也有不同的类型:赋值i=j会引起一个类型错误,必须使用显式转换:i=int(j)。
变量f的类型为float,当前实现将其表示为32位浮点值。它具有与int32相同的内存占用空间,但内部布局不同。
结构体及其指针
现在情况开始变得有趣。变量bytes的类型为[5]byte,是一个由5个字节组成的数组。它的内存表示就是这5个字节,一个接一个,就像一个C数组。类似地,primes是一个由4个int组成的数组。
Go与C一样,但与Java不一样,它可以让程序员控制什么是指针,什么不是指针。例如,此类型定义:
type Point struct { X, Y int }定义了一个名为Point的简单结构体类型,表现在内存中就是两个相邻的int字段。
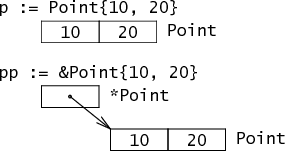
复合字面量语法Point{10, 20}表示已初始化的一个Point实例。获取Point{10, 20}的地址&Point{10, 20}表示指向Point{10, 20}的指针。前者是内存中的两个字(word);后者是指向内存中这两个字的指针。
结构体中的字段在内存中并排排列。
type Rect1 struct { Min, Max Point }
type Rect2 struct { Min, Max *Point }
Rect1是一个具有两个Point字段的结构体,在内存中由一行中的两个Point字段(四个int)表示。Rect2是一个具有两个*Point字段的结构体。
使用过C语言的程序员可能不会对Point字段和*Point字段之间的区别感到惊讶,而只使用过Java或Python(或…)的程序员可能会感到惊讶。通过让程序员控制基本的内存布局,Go提供了控制给定数据结构集合的总大小、分配的元素的数量和内存访问模式的能力,所有这些对于构建性能良好的系统都很重要。
字符串
有了这些预备知识,我们可以继续研究更有趣的数据类型。

(灰色箭头表示字符串实现中存在但在程序中不直接可见的指针。)
一个字符串string在内存中表示为一个2字结构体,里面包含一个指向字符串数据(是一个字节数组)的指针和一个长度字段。由于字符串是不可变类型,因此多个字符串共享同一底层存储是安全的,因此对s进行切片会产生一个新的2字结构体,该结构体具有不同的指针和长度字段,但仍然引用相同的底层字节序列。这意味着可以在不重新分配或复制的情况下进行切片,从而使字符串切片与显式地使用下标索引一样高效。
(顺便说一句,Java和其他语言中有一个众所周知的难题,当你对一个字符串进行切片以保存一小段时,对原始字符串的引用会将整个原始字符串保留在内存中,即使只需要少量的字符串。Go也有这个难题。我们尝试过但拒绝了另一种选择,那就是让字符串切片变得如此昂贵——一次再分配和一个新副本——大多数程序都应该避开它。)
切片(slice)

切片是对某个数组的部分引用。在内存中,它是一个3字结构体,包含指向第一个数组元素的指针、切片的长度和容量。长度是x[i]等索引操作的上限,而容量是x[i:j]等切片操作的上限。
与对字符串进行切片一样,对数组进行切片不会产生新副本:它只会创建一个包含不同指针、长度和容量的新结构体。在本例中,一开始创建切片[]int{2,3,5,7,11}在底层会创建一个包含五个值的新数组,然后设置切片x的字段来描述该数组。但切片表达式x[1:3]没有分配更多的数据:它只是创建一个新的切片头结构体,以引用相同的底层数组。在本例中,它的长度为2,即y[0],y[1]是唯一有效的索引,但容量为4,即y[0:4]是有效的切片表达式。(有关长度和容量以及切片使用方式的详细信息,请参阅Effective Go。)
因为切片是多字结构体,而不是指针,所以切片操作不需要分配内存,甚至不需要为切片头分配内存,因为切片头通常可以保存在栈上。这种切片的使用成本与在C语言中显式传递指针和长度对一样低。Go最初将切片表示为指向上述结构体的指针,但这样做意味着每个切片操作都会分配一个新的内存对象。即使使用快速的内存分配器,也会给垃圾收集器带来很多不必要的工作。不使用指针和分配内存使得切片足够便宜。
new和make
Go有两个数据结构创建函数:new和make。它们的区别在早期是一个常见的混淆点,但似乎很快就变得很自然了。基本区别是new(T)返回一个*T,Go程序可以隐式地解引用该指针(下图中的黑色指针),而make(T,args)返回普通的T,而不是指针。通常,T内部有一些隐式指针(下图中的灰色指针)。new返回一个指向值全是0的一块内存区域的指针(如下图所示),而make返回一个复杂的结构体。
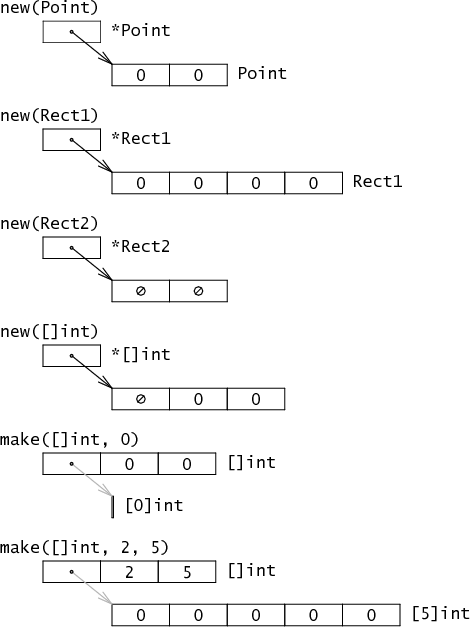
有一种方法可以将这两者统一起来,但这将是对C和C++传统的重大突破:定义make(*T)返回一个指向新分配的T的指针,这样当前的new(Point)就可以被改写为make(*Point)。我们尝试了几天,但认为这与人们对分配函数的期望太不一样了。
更多……
这已经有点长了。接口(interface)、映射(map)和通道(channel)将不得不等待将来的发布。