本文翻译自《Tutorial: Getting started with fuzzing》。
本教程介绍Go中模糊测试的基本知识。通过模糊测试,随机数据会针对你的测试程序运行,试图找到程序漏洞或导致程序崩溃的输入。模糊测试可以发现的一些漏洞包括SQL注入、缓冲区溢出、拒绝服务和跨站点脚本攻击等。
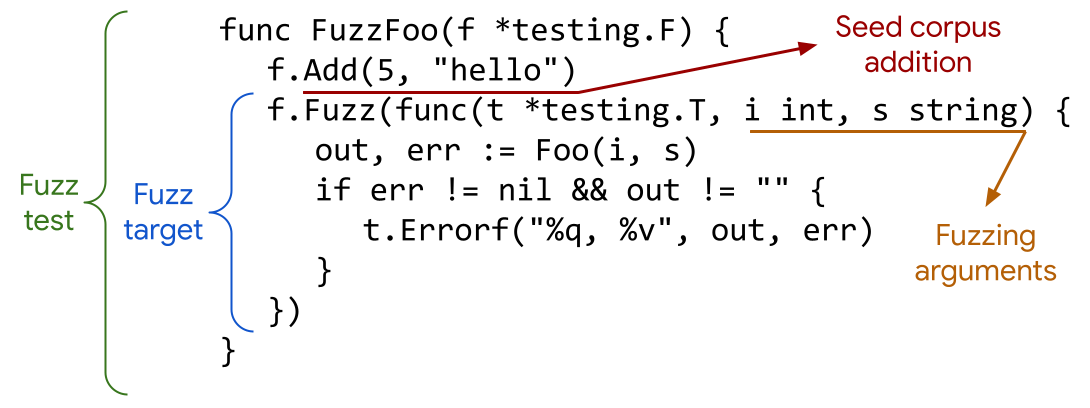
有关本教程中的术语,请参阅Go Fuzzing词汇表。
你将完成以下部分:
1 为代码创建一个文件夹。
2 添加要测试的代码。
3 添加一个单元测试。
4 添加一个模糊测试。
5 修复两个Bug。
6 探索其他资源。
注意:有关其他教程,请参见教程
注意:Go fuzzing目前支持Go fuzzing文档中列出的一个内置类型子集,并会在未来添加更多的内置类型。
先决条件
- 安装Go 1.18或更高版本。有关安装说明,请参阅安装Go。
- 用于编辑代码的工具。你拥有的任何文本编辑器都可以正常工作。
- 一种命令行终端。Go在Linux和Mac上使用任何终端都能很好地工作,以及Windows中的PowerShell或CMD。
- 支持模糊测试的运行环境。带覆盖检测的Go fuzzing目前仅在AMD64和ARM64架构上可用。
为代码创建一个文件夹
首先,为要编写的代码创建一个文件夹。
1 打开命令提示符并转到家目录。 在Linux或Mac上:
$ cd
在Windows:
C:\> cd %HOMEPATH%
本教程的其余部分将显示一个$作为提示符。本教程使用的命令也适用于Windows。
2.在命令提示符下,为代码创建一个名为fuzz的目录。
$ mkdir fuzz
$ cd fuzz
3.创建一个模块来保存代码。
运行go mod init命令,给出代码的模块路径:
$ go mod init example/fuzz
go: creating new go.mod: module example/fuzz
注意:对于生产代码,你应该指定一个更适合你自己需求的模块路径。有关详细信息,请参阅管理依赖关系。
接下来,你将添加一些简单的代码来反转字符串,稍后我们将对其进行模糊测试。
添加要测试的代码
在这一步中,你将添加一个函数来反转字符串。
编写代码
1.使用文本编辑器,在fuzz目录中创建一个名为main.go的文件。
2.在main.go文件顶部,粘贴以下包声明:
package main
独立程序(与库相对)始终位于main包中。
3.在包声明下面,粘贴以下函数声明:
func Reverse(s string) string {
b := []byte(s)
for i, j := 0, len(b)-1; i < len(b)/2; i, j = i+1, j-1 {
b[i], b[j] = b[j], b[i]
}
return string(b)
}
此函数将接受一个字符串,一次循环一个字节,最后返回反转后的字符串。
注:此代码基于golang.org/x/example中的stringutil.Revirse函数。
4.在main.go的顶部,在包声明的下面,粘贴以下main函数来初始化字符串,反转它,打印输出,然后重复:
func main() {
input := "The quick brown fox jumped over the lazy dog"
rev := Reverse(input)
doubleRev := Reverse(rev)
fmt.Printf("original: %q\n", input)
fmt.Printf("reversed: %q\n", rev)
fmt.Printf("reversed again: %q\n", doubleRev)
}
此函数将运行一些反转字符串的操作,然后将输出打印到命令行。这有助于查看运行中的代码,并可能有助于调试。
5.main函数使用fmt包,因此需要导入它。 第一行代码应该如下所示:
package main
import "fmt"
运行代码
在包含main.go的目录的命令行中,运行代码:
$ go run .
original: "The quick brown fox jumped over the lazy dog"
reversed: "god yzal eht revo depmuj xof nworb kciuq ehT"
reversed again: "The quick brown fox jumped over the lazy dog"
你可以看到原始字符串,反转后的结果,然后再次反转的结果,这等于原始字符串。
现在代码已经能够运行,是时候对其进行测试了。
添加一个单元测试
在这一步中,你将为Reverse函数编写一个基本的单元测试。
编写代码
1.使用文本编辑器,在fuzz目录中创建一个名为reverse_test.go的文件。
2.将以下代码粘贴到reverse_test.go中:
package main
import (
"testing"
)
func TestReverse(t *testing.T) {
testcases := []struct {
in, want string
}{
{"Hello, world", "dlrow ,olleH"},
{" ", " "},
{"!12345", "54321!"},
}
for _, tc := range testcases {
rev := Reverse(tc.in)
if rev != tc.want {
t.Errorf("Reverse: %q, want %q", rev, tc.want)
}
}
}
这个简单的测试将断言列出的输入字符串将被正确地反转。
运行代码
使用go test运行单元测试:
$ go test
PASS
ok example/fuzz 0.013s
接下来,你将把单元测试更改为模糊测试。
添加一个模糊测试
单元测试有局限性,即每个输入都必须由开发人员添加到测试中。模糊测试的一个好处是,它为你的代码提供输入,并可能识别出你给出的测试用例没有达到的边缘条件。
在本节中,你将把单元测试转换为模糊测试,这样你就可以用更少的工作生成更多的输入!
请注意,你可以将单元测试、基准测试和模糊测试放在同一个*_test.go文件中,但在本例中,你将把单元测试转换为模糊测试。
编写代码
在文本编辑器中,将reverse_test.go中的单元测试替换为以下模糊测试:
func FuzzReverse(f *testing.F) {
testcases := []string{"Hello, world", " ", "!12345"}
for _, tc := range testcases {
f.Add(tc) // 使用f.Add函数提供一个种子测试用例
}
f.Fuzz(func(t *testing.T, orig string) {
rev := Reverse(orig)
doubleRev := Reverse(rev)
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", orig, doubleRev)
}
if utf8.ValidString(orig) && !utf8.ValidString(rev) {
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
}
})
}
模糊测试也有一些局限性。在单元测试中,你可以预测Reverse函数的预期输出,并验证实际输出是否满足这些预期。
例如,在测试用例Reverse("Hello, world")中,单元测试预期其输出为"dlrow, olleH"。
使用模糊测试时,你无法预测输出,因为你无法控制输入。
不过,你可以在模糊测试中验证Reverse函数的一些特性。在这个模糊测试中检查的两个属性是:
- 将字符串反转两次后将和原始值相同。
- 反转后的字符串的编码应该是有效的UTF-8。
请注意单元测试和模糊测试之间的语法差异:
- 该函数以
FuzzXxx而不是TestXxx开始,并且参数类型采用*testing.F而不是*test.T。 - 在你期望看到
t.Run的地方,你会看到f.Fuzz,它接受一个目标函数,其参数的类型是*testing.T和要模糊测试的类型。单元测试的输入使用f.Add作为一个种子语料库提供给模糊测试。
请确保已导入新的程序包unicode/utf8:
package main
import (
"testing"
"unicode/utf8"
)
随着单元测试转换为模糊测试,是时候再次运行测试了。
运行代码
1.在不模糊的情况下运行模糊测试,以确保种子输入通过。
$ go test
PASS
ok example/fuzz 0.013s
如果该文件中有其他测试,并且你只希望运行模糊测试,那么你可以执行go test -run=FuzzReverse。
2.运行FuzzReverse函数进行模糊测试,查看任何随机生成的字符串作为输入是否会导致该函数执行失败。这也是使用go test命令执行的,使用一个新的标志-fuzz,设置它的参数值为Fuzz:
$ go test -fuzz=Fuzz
另一个有用的标志是-fuzzztime,它限制模糊测试所能花费的时间。例如,在下面的测试中指定-fuzztime 10s意味着,只要之前没有发生测试失败,测试将在10秒后退出。请参阅cmd/go文档的这一部分,以查看其他标志。
现在,运行刚才复制的命令:
$ go test -fuzz=Fuzz
fuzz: elapsed: 0s, gathering baseline coverage: 0/3 completed
fuzz: elapsed: 0s, gathering baseline coverage: 3/3 completed, now fuzzing with 8 workers
fuzz: minimizing 38-byte failing input file...
--- FAIL: FuzzReverse (0.01s)
--- FAIL: FuzzReverse (0.00s)
reverse_test.go:20: Reverse produced invalid UTF-8 string "\x9c\xdd"
Failing input written to testdata/fuzz/FuzzReverse/af69258a12129d6cbba438df5d5f25ba0ec050461c116f777e77ea7c9a0d217a
To re-run:
go test -run=FuzzReverse/af69258a12129d6cbba438df5d5f25ba0ec050461c116f777e77ea7c9a0d217a
FAIL
exit status 1
FAIL example/fuzz 0.030s
模糊测试时如果发生测试失败,导致问题的输入就会被写入种子语料库文件,该文件将在下次调用go test时运行,即使没有使用-fuzz标志。要查看导致测试失败的输入,请在文本编辑器中打开testdata/fuzz/FuzzReverse目录里的语料库文件。种子语料库文件可能包含不同的字符串,但格式是一样的。
go test fuzz v1
string("泃")
语料库文件的第一行指示编码版本。下面的每一行表示组成语料库条目的每种类型的值。由于本例模糊测试的目标只接受1个输入,因此版本号之后只有1个值。
3.在没有使用-fuzz标志的情况下再次运行go test;将使用新的导致测试失败的种子语料库条目:
$ go test
--- FAIL: FuzzReverse (0.00s)
--- FAIL: FuzzReverse/af69258a12129d6cbba438df5d5f25ba0ec050461c116f777e77ea7c9a0d217a (0.00s)
reverse_test.go:20: Reverse produced invalid string
FAIL
exit status 1
FAIL example/fuzz 0.016s
既然我们的测试失败了,是时候调试了。
修复两个Bug
修复非法字符串Bug
在本节中,你将调试故障并修复Bug。
在继续之前,你可以花一些时间思考这个问题,并尝试自己解决这个问题。
诊断这个错误
有几种不同的方法可以调试此错误。如果使用VS代码作为文本编辑器,则可以设置调试器进行调查。
在本教程中,我们将把有用的调试信息记录到终端。 首先,考虑utf8.ValidString的文档:
ValidString reports whether s consists entirely of valid UTF-8-encoded runes.
当前的Reverse函数逐字节反转字符串,这就是我们的问题所在。为了保留原始字符串的UTF-8编码的字符,我们必须逐字符反转字符串。
检查为什么输入(在本例是汉字“泃”) 导致反转时Reverse生成一个无效字符串,你可以检查反转后的字符串中的字符个数。
编写代码
在文本编辑器中,用以下内容替换FuzzReverse函数中的模糊测试的目标函数:
f.Fuzz(func(t *testing.T, orig string) {
rev := Reverse(orig)
doubleRev := Reverse(rev)
t.Logf("Number of runes: orig=%d, rev=%d, doubleRev=%d", utf8.RuneCountInString(orig), utf8.RuneCountInString(rev), utf8.RuneCountInString(doubleRev))
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", orig, doubleRev)
}
if utf8.ValidString(orig) && !utf8.ValidString(rev) {
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
}
})
如果发生错误,或者使用-v执行测试,则此t.Logf将打印日志信息到命令行,这可以帮助你调试此特定问题。
运行代码
使用go test运行测试:
$ go test
--- FAIL: FuzzReverse (0.00s)
--- FAIL: FuzzReverse/28f36ef487f23e6c7a81ebdaa9feffe2f2b02b4cddaa6252e87f69863046a5e0 (0.00s)
reverse_test.go:16: Number of runes: orig=1, rev=3, doubleRev=1
reverse_test.go:21: Reverse produced invalid UTF-8 string "\x83\xb3\xe6"
FAIL
exit status 1
FAIL example/fuzz 0.598s
整个种子语料库使用的字符串,其中每个字符都是一个字节。但是,诸如“泃”字符可能占用几个字节。因此,逐字节反转字符串将使多字节字符无效。
注意:如果你对Go如何处理字符串感到好奇,请阅读博客文章《Go中的字符串、字节、rune和字符》,以获得更加深入的理解。
对上述Bug有了更好的了解后,请你更正Reverse函数中的错误。
修复Bug
要更正Reverse函数,让我们按rune而不是按字节遍历字符串。
编写代码
在文本编辑器中,将现有的Reverse函数替换为以下函数:
func Reverse(s string) string {
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r)
}
关键的区别在于,Reverse现在迭代字符串中的每个符文,而不是每个字节。
运行代码
1.使用go test运行测试
$ go test
PASS
ok example/fuzz 0.016s
现在测试通过了!
2.用go test -fuzz再次模糊测试它,看看是否有任何新的bug
$ go test -fuzz=Fuzz
fuzz: elapsed: 0s, gathering baseline coverage: 0/37 completed
fuzz: minimizing 506-byte failing input file...
fuzz: elapsed: 0s, gathering baseline coverage: 5/37 completed
--- FAIL: FuzzReverse (0.02s)
--- FAIL: FuzzReverse (0.00s)
reverse_test.go:33: Before: "\x91", after: "�"
Failing input written to testdata/fuzz/FuzzReverse/1ffc28f7538e29d79fce69fef20ce5ea72648529a9ca10bea392bcff28cd015c
To re-run:
go test -run=FuzzReverse/1ffc28f7538e29d79fce69fef20ce5ea72648529a9ca10bea392bcff28cd015c
FAIL
exit status 1
FAIL example/fuzz 0.032s
我们可以看到,经过两次反转后,字符串与原来的字符串不同。这一次输入本身就是无效的unicode。这怎么可能发生呢?
让我们再次调试。
修复两次逆转字符串产生的Bug
在本节中,你将调试两次逆转字符串产生的Bug并修复该Bug。
在继续之前,你可以花一些时间思考这个问题,并尝试自己解决这个问题。
诊断这个错误
和以前一样,有几种方法可以调试此Bug。使用调试器(debugger)将是一种很好的方法。
在本教程中,我们将在Reverse函数中记录有用的调试信息。 仔细观察反转的字符串以发现此Bug。在Go中,一个字符串是一个只读的字节切片(a string is a read only slice of bytes),可以包含非UTF-8的字节。原始字符串是一个带有一个字节“\x91”的字节切片。当输入字符串被转换为[]rune时,Go将字节切片编码为UTF-8字符切片,并将第一个字节“\x91”替换为一个UTF-8字符�。当我们将这个UTF-8字符与原始字节切片进行比较时,它们显然不相等。
编写代码
1.在文本编辑器中,将Reverse函数替换为以下内容。
func Reverse(s string) string {
fmt.Printf("input: %q\n", s)
r := []rune(s)
fmt.Printf("runes: %q\n", r)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r)
}
这将帮助我们了解在将字符串转换为rune切片时出现的问题。
运行代码
这一次,我们只想运行失败的测试来检查日志。为此,我们将使用go test -run。 要在FuzzXxx/testdata中运行特定的语料库条目,可以提供{FuzzTestName}/{filename}来运行。这在调试时很有帮助。在这种情况下,将-run标志设置为等于测试失败的测试用例的散列值。从你的终端复制并粘贴唯一的散列值,它可能与下面的不同:
$ go test -run=FuzzReverse/28f36ef487f23e6c7a81ebdaa9feffe2f2b02b4cddaa6252e87f69863046a5e0
input: "\x91"
runes: ['�']
input: "�"
runes: ['�']
--- FAIL: FuzzReverse (0.00s)
--- FAIL: FuzzReverse/28f36ef487f23e6c7a81ebdaa9feffe2f2b02b4cddaa6252e87f69863046a5e0 (0.00s)
reverse_test.go:16: Number of runes: orig=1, rev=1, doubleRev=1
reverse_test.go:18: Before: "\x91", after: "�"
FAIL
exit status 1
FAIL example/fuzz 0.145s
我们知道了输入是无效的unicode字符,让我们修复Reverse函数中的Bug。
修复Bug
为了解决这个问题,如果Reverse的输入不是有效的UTF-8编码的字符串,我们就返回一个错误。
编写代码
1.在文本编辑器中,用以下内容替换现有的Reverse函数。
func Reverse(s string) (string, error) {
if !utf8.ValidString(s) {
return s, errors.New("input is not valid UTF-8")
}
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r), nil
}
如果输入的字符串包含无效的UTF-8字符,则返回一个错误。
2.由于Reverse函数现在返回一个错误,修改main函数的代码以丢弃额外的错误值。
func main() {
input := "The quick brown fox jumped over the lazy dog"
rev, revErr := Reverse(input)
doubleRev, doubleRevErr := Reverse(rev)
fmt.Printf("original: %q\n", input)
fmt.Printf("reversed: %q, err: %v\n", rev, revErr)
fmt.Printf("reversed again: %q, err: %v\n", doubleRev, doubleRevErr)
}
这些对Reverse函数的调用应该返回nil错误(没有错误发生),因为输入的字符串是有效的UTF-8编码。
3.将需要导入errors和unicode/utf8包。main.go中的import语句应该如下所示。
import (
"errors"
"fmt"
"unicode/utf8"
)
4.修改reverse_test.go文件以检查错误,如果Reverse函数返回了一个错误,则跳过本次测试。
func FuzzReverse(f *testing.F) {
testcases := []string {"Hello, world", " ", "!12345"}
for _, tc := range testcases {
f.Add(tc) // Use f.Add to provide a seed corpus
}
f.Fuzz(func(t *testing.T, orig string) {
rev, err1 := Reverse(orig)
if err1 != nil {
return
}
doubleRev, err2 := Reverse(rev)
if err2 != nil {
return
}
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", orig, doubleRev)
}
if utf8.ValidString(orig) && !utf8.ValidString(rev) {
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
}
})
}
如果不想用直接return的话,你也可以调用t.Skip()函数来停止执行本次模糊测试。
运行代码
1.使用go test运行测试
$ go test
PASS
ok example/fuzz 0.019s
2.用go test -fuzz=Fuzz运行模糊测试,然后几秒钟后,用组合键ctrl-C停止模糊测试。模糊测试将一直运行,直到遇到失败的输入,或者你通过-fuzztime标志指定最长运行时间。默认情况下,如果没有发生测试失败,模糊测试将永远运行下去,但可以使用组合键ctrl-C中断进程。
$ go test -fuzz=Fuzz
fuzz: elapsed: 0s, gathering baseline coverage: 0/38 completed
fuzz: elapsed: 0s, gathering baseline coverage: 38/38 completed, now fuzzing with 4 workers
fuzz: elapsed: 3s, execs: 86342 (28778/sec), new interesting: 2 (total: 35)
fuzz: elapsed: 6s, execs: 193490 (35714/sec), new interesting: 4 (total: 37)
fuzz: elapsed: 9s, execs: 304390 (36961/sec), new interesting: 4 (total: 37)
...
fuzz: elapsed: 3m45s, execs: 7246222 (32357/sec), new interesting: 8 (total: 41)
^Cfuzz: elapsed: 3m48s, execs: 7335316 (31648/sec), new interesting: 8 (total: 41)
PASS
ok example/fuzz 228.000s
3.使用go test -fuzz=Fuzz -fuzztime 30s,如果没有遇到测试失败的用例,总共将进行30秒时间的模糊测试。
$ go test -fuzz=Fuzz -fuzztime 30s
fuzz: elapsed: 0s, gathering baseline coverage: 0/5 completed
fuzz: elapsed: 0s, gathering baseline coverage: 5/5 completed, now fuzzing with 4 workers
fuzz: elapsed: 3s, execs: 80290 (26763/sec), new interesting: 12 (total: 12)
fuzz: elapsed: 6s, execs: 210803 (43501/sec), new interesting: 14 (total: 14)
fuzz: elapsed: 9s, execs: 292882 (27360/sec), new interesting: 14 (total: 14)
fuzz: elapsed: 12s, execs: 371872 (26329/sec), new interesting: 14 (total: 14)
fuzz: elapsed: 15s, execs: 517169 (48433/sec), new interesting: 15 (total: 15)
fuzz: elapsed: 18s, execs: 663276 (48699/sec), new interesting: 15 (total: 15)
fuzz: elapsed: 21s, execs: 771698 (36143/sec), new interesting: 15 (total: 15)
fuzz: elapsed: 24s, execs: 924768 (50990/sec), new interesting: 16 (total: 16)
fuzz: elapsed: 27s, execs: 1082025 (52427/sec), new interesting: 17 (total: 17)
fuzz: elapsed: 30s, execs: 1172817 (30281/sec), new interesting: 17 (total: 17)
fuzz: elapsed: 31s, execs: 1172817 (0/sec), new interesting: 17 (total: 17)
PASS
ok example/fuzz 31.025s
模糊测试通过了!
除了-fuzz标志之外,还添加了几个新的标志,可以在文档中查看。
有关模糊测试输出中使用的术语的更多信息,请参阅文章Go模糊测试。例如,“new interesting”指的是扩展了代码覆盖率的已存在的模糊测试语料库的输入。在模糊测试的一开始,“new interesting”输入的数量会急剧增加,随着新的代码路径的发现,“new interesting”输入的数量还会激增几次,然后随着时间的推移逐渐减少。
结论
得好!你刚刚向自己介绍了Go中的模糊测试。
下一步是在代码中选择一个你想模糊测试的函数,并尝试它!如果模糊测试在你的代码中发现了一个错误,请考虑将其添加到trophy case(译者注:向别人炫耀你发现的Go标准库Bug)中。
如果你遇到任何问题或对某个功能有想法,请在此提交问题。
对于有关模糊测试的功能的讨论和反馈,你也可以加入Gophers Slack中的#fuzzing频道。 请查看go.dev/security/fuzz上的文档以获得进一步的阅读。
完整的代码
以下是本文中出现过的全部代码:
— main.go —
package main
import (
"errors"
"fmt"
"unicode/utf8"
)
func main() {
input := "The quick brown fox jumped over the lazy dog"
rev, revErr := Reverse(input)
doubleRev, doubleRevErr := Reverse(rev)
fmt.Printf("original: %q\n", input)
fmt.Printf("reversed: %q, err: %v\n", rev, revErr)
fmt.Printf("reversed again: %q, err: %v\n", doubleRev, doubleRevErr)
}
func Reverse(s string) (string, error) {
if !utf8.ValidString(s) {
return s, errors.New("input is not valid UTF-8")
}
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r), nil
}
— reverse_test.go —
package main
import (
"testing"
"unicode/utf8"
)
func FuzzReverse(f *testing.F) {
testcases := []string{"Hello, world", " ", "!12345"}
for _, tc := range testcases {
f.Add(tc) // Use f.Add to provide a seed corpus
}
f.Fuzz(func(t *testing.T, orig string) {
rev, err1 := Reverse(orig)
if err1 != nil {
return
}
doubleRev, err2 := Reverse(rev)
if err2 != nil {
return
}
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", orig, doubleRev)
}
if utf8.ValidString(orig) && !utf8.ValidString(rev) {
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
}
})
}